
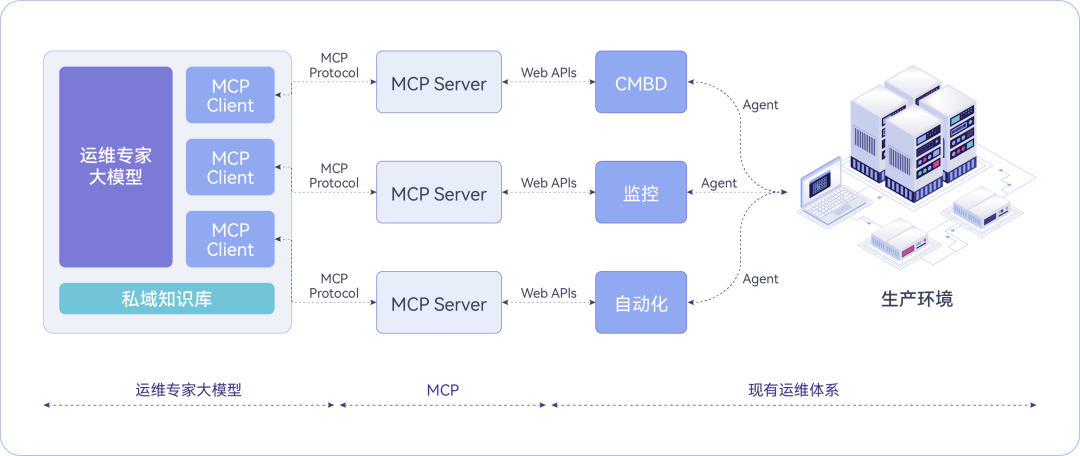

——一篇不讲概念堆砌、只讲落地逻辑的深度技术文
在很多单位,CMDB 都有一种熟悉的命运:
立项时:
“这是运维的中枢大脑,是数字化运维的基石。”
上线后:
“没人维护、没人用、数据不准,最后只剩一个系统壳。”
问题不在工具,而在认知和方法论。
这篇文章不从“定义背书”写起,而是站在一线运维与架构视角,把 CMDB 的本质、误区、建设路径和长期维护机制一次讲透。
一、先说人话:CMDB 到底是什么?
一句话定义
CMDB 不是“资产台账系统”,而是“运维事实的唯一真相源(Single Source of Truth)”。
它回答的不是“你有多少设备”,而是:
现在
哪台设备
在什么环境
跑着什么系统
提供什么服务
依赖谁、被谁依赖
出问题时
会影响哪些系统
找谁、怎么处置
二、为什么 80% 的 CMDB 都会失败?
在谈“怎么建”之前,必须先把坑挖出来。
❌ 典型失败 CMDB 的特征
❗ 根本原因只有一个
把 CMDB 当“管理系统”,而不是“运维系统”。
三、CMDB 的本质:不是“存数据”,而是“建关系”
1️⃣ 运维真正关心的不是“设备”,而是“关系链”
单台服务器的信息,毫无价值
真正有价值的是这条链:
业务系统
└─ 应用服务
└─ 主机 / 容器
└─ 网络 / 存储
└─ 机房 / 区域
CMDB 的核心不是表,而是关系模型。
2️⃣ CMDB 中最重要的 5 类对象(CI)
没有“人”的 CMDB,是不能用于运维的。
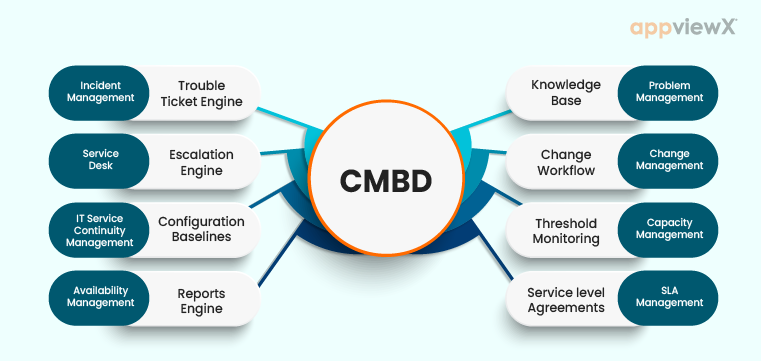
四、从 0 到 1:CMDB 建设的正确顺序
❌ 错误顺序(最常见)
选工具 → 设计字段 → 填表 → 上线 → 烂尾✅ 正确顺序(运维可持续)
明确场景 → 定义最小模型 → 自动采集 → 强绑定流程 → 持续演进下面一步一步拆。
五、第 1 步:先选“一个必须用 CMDB 的场景”
不要一开始就想“全覆盖”。
推荐的 3 个切入点(选一个)
✅ 场景一:监控告警关联
告警出来 → 自动知道:
这台机器属于哪个系统
负责人是谁
影响级别
这是 CMDB 最容易体现价值的地方
✅ 场景二:变更 / 发布管理
上线前:
变更影响哪些 CI?
出问题:
快速回溯最近变更
✅ 场景三:安全 / 合规 / 台账
哪些系统是涉密 / 商密?
哪些资产到期、违规、未备案?
建议从“监控 + 告警”切入,阻力最小。
六、第 2 步:设计“最小可用 CMDB 模型”
❗ 核心原则:字段越少,生命周期越长
一个“能跑起来”的最小模型示例
① 主机 CI(必须字段)
② 系统 CI
注意:字段不是“以后可能用”,而是“现在必须用”。
七、第 3 步:自动采集是生死线
任何靠人工长期维护的数据,最终都会失真。
必须自动采集的内容
关键理念
人负责 确认
系统负责 发现
CMDB 负责 承载
八、第 4 步:让 CMDB “被迫准确”
❗ 真正有效的方法只有一个
不更新 CMDB,就干不了活。
典型绑定方式
🔗 与告警系统绑定
告警必须能关联 CI
CI 无负责人 → 告警无法升级
🔗 与工单 / 变更绑定
工单必须选择 CI
CI 信息不全 → 不允许提交
CMDB 的准确性,来自“流程约束”,不是自觉。
九、第 5 步:CMDB 的长期维护机制
1️⃣ 生命周期管理(极其重要)
每个 CI 都必须有状态:
规划中 → 在用 → 待下线 → 已下线没有“下线”的 CMDB,一定会爆炸。
2️⃣ 定期“对账机制”
3️⃣ 角色分工
十、成熟 CMDB 的 3 个标志
如果你的 CMDB 做到了下面三点,说明它已经“活了”:
告警、变更、安全都离不开它
数据主要来自自动发现
没人质疑它是不是“准”
十一、结语:CMDB 不是项目,而是“能力”
最后说一句很重要的话:
CMDB 永远不可能“建完”,它只能“逐步成熟”。
它不是一个上线节点,而是一条运维能力曲线。
初级:台账
中级:关系
高级:决策支撑