
周期性重启(比如每 2 小时一次)几乎都不是“随机故障”。
这类问题的本质只有三种:
1)有人/任务在主动重启(cron/systemd timer/平台策略)
2)系统自己在保护性重启(watchdog、panic、oom、kdump)
3)外部力量把它“断电”(BMC/IPMI/虚拟化平台/电源/机房)
你要做的是把“重启”拆成三段证据链:
有没有真实重启?什么时候重启?(时间轴)
是谁触发的?(触发源:用户/服务/内核/外部)
重启前 1~5 分钟发生了什么?(前因)
下面按这个顺序走,你能把问题定位到非常具体的责任点。
一、先把“重启时间轴”钉死
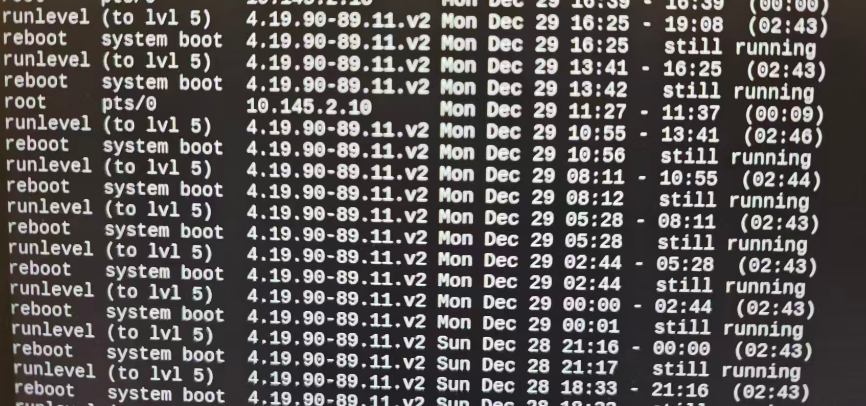
1)快速看历史重启记录
last -x | head -n 50
你会看到类似:
reboot system boot ...shutdown system down ...
如果真的每 2 小时一次,这里会出现非常规律的时间点。
2)核对系统启动时间(确认当前这次)
who -b
uptime
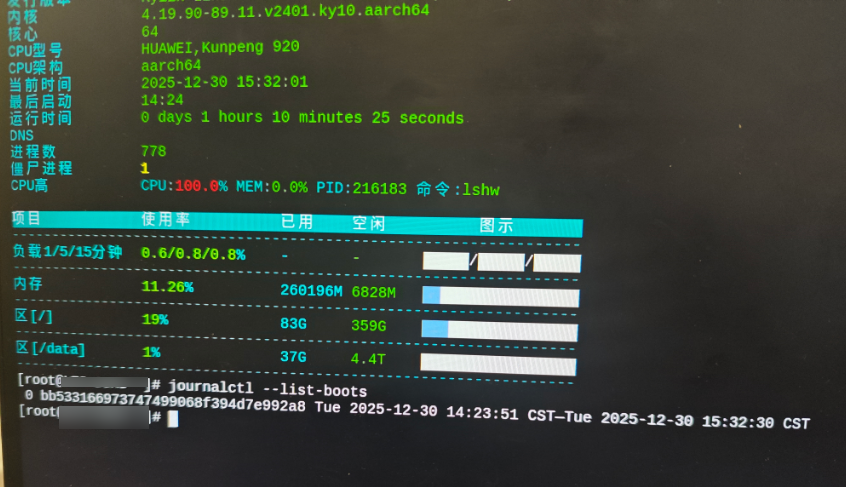
3)更准确的启动 ID(systemd 系统强烈推荐)
journalctl --list-boots这会列出每次启动的 boot-id 和时间范围,后面所有分析都靠它。
二、判断是“正常重启”还是“异常崩溃”
关键:重启前有没有“正常关机流程”的日志?
1)看上一轮启动末尾的关机原因
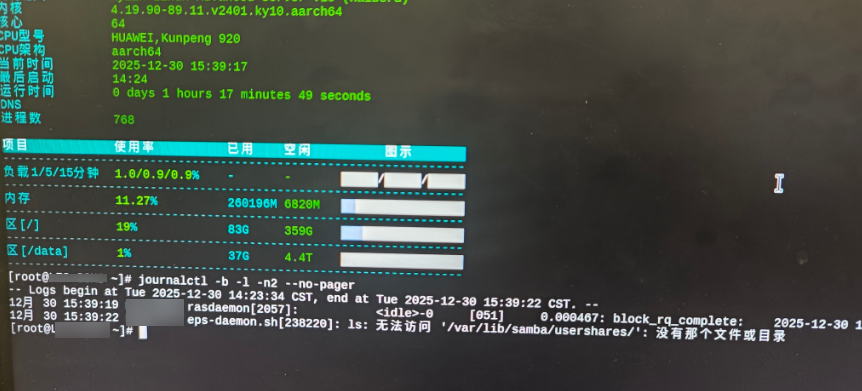
先拿到“上一次启动”的范围:
journalctl -b -l -n 200 --no-pager如果你看到:
systemd: Reached target Shutdownsystemd: Stopping ...systemd-shutdown: Syncing filesystems...
这说明是正常关机流程 → 大概率是人为/任务/平台发起。
如果你看到:
日志突然断了、最后是内核报错、I/O error、panic
或者根本没有 shutdown 过程
这说明是异常崩溃/断电/硬复位 → 大概率是内核/硬件/外部强制。
三、定位“谁发起了重启”(最常见:定时任务/策略)
A. 系统里是否有人执行了 reboot/shutdown(最直接)
journalctl -b -1 | egrep -i "reboot|shutdown|poweroff|halt|systemd-logind|Requested reboot|Restarting system"还要看“是谁”:
journalctl -b -1 | egrep -i "USER|sudo|COMMAND=|session opened|session closed" | tail -n 200如果你看到:
sudo: user : COMMAND=/sbin/rebootsystemd-logind: Power key pressed(少见)systemd: Rebooting.
那基本就稳了:人为或脚本触发。
B. 两小时一次:第一嫌疑人就是 cron / systemd timer
1)查系统级 cron
cat /etc/crontab
ls -l /etc/cron.d/
ls -l /etc/cron.hourly/ /etc/cron.daily/ /etc/cron.weekly/
2)查 root 的个人 cron(最容易藏“重启脚本”)
crontab -l
sudo crontab -l
3)查 systemd timers(现代系统更常用)
systemctl list-timers --all
然后重点查“最近两小时触发过什么”:
journalctl -u <timer相关的service名> -S "2 hours ago" --no-pager
技巧:凡是 timer 名字里带 upgrade、patch、maintain、health、watchdog、reboot 之类关键词,优先怀疑。
C. 企业环境常见:运维平台/安全策略“定点重启”
如果你在国企/内网环境(比如堡垒机、统一运维平台、EDR/基线工具),经常会有:
基线检查策略
自动打补丁策略
自动修复策略(修复=重启)
建议你直接查:
平台 agent 的日志目录(例如
/var/log/xxx-agent/)相关服务:
systemctl list-units --type=service | egrep -i "agent|edr|ops|maint|patch|baseline"
四、如果不是“正常关机”:重点看内核级原因(panic / watchdog / OOM)
A. 内核 panic / 崩溃(重启最典型)
journalctl -k -b -1 --no-pager | tail -n 300
重点关键字:
panicOopsBUG:Call TraceKernel watchdoghard LOCKUPsoft LOCKUP
如果出现 panic,下一步查:
是否开启 kdump(是否生成 vmcore)
systemctl status kdump 2>/dev/null
ls -lh /var/crash/
B. watchdog 触发(“两小时”有时是 watchdog/心跳超时)
看 watchdog 相关:
journalctl -b -1 | egrep -i "watchdog|soft lockup|hard lockup|NMI watchdog"
还要检查是否启用了硬件 watchdog 服务:
systemctl status watchdog 2>/dev/null
lsmod | grep watchdog
C. OOM(内存打爆导致服务异常,极端时触发重启链路)
journalctl -b -1 | egrep -i "oom|Out of memory|Killed process"
如果你看到 OOM,接着查:
哪个进程吃内存
是否 cgroup 限制、容器压力
是否 swap 配置不当
五、如果日志像“被刀切断”:优先怀疑断电/外部强制重启
这类情况你会看到:
系统日志没有 shutdown 流程
journal 直接断在某一行
A. 物理机:查 BMC/IPMI(非常关键)
如果是服务器(iDRAC/iLO/BMC),去 BMC 里看:
System Event Log(SEL)
Power events(断电/重上电)
Thermal(过温保护)
PSU(电源异常)
Linux 侧也能查一点(有 ipmitool 的话):
ipmitool sel list
ipmitool chassis status
B. 虚拟机:查宿主机/平台事件
如果是 VMware / KVM / 云平台,去平台看:
VM 重启策略(HA/健康检查)
宿主机重启迁移事件
电源操作审计日志
六、给你一套“付费级”一键定位流程(照抄就能复盘)
目标:把每次重启前 3 分钟的关键信息自动抓出来,形成证据包。
1)拿到最近一次重启前后的时间范围
journalctl --list-boots
找到 -1 那次的起止时间。
2)导出上一次启动末尾 10 分钟的全量日志
journalctl -b -1 --no-pager -S "-10min" > /tmp/boot_minus1_last10min.log
3)导出关键维度
journalctl -b -1 -k --no-pager > /tmp/boot_minus1_kernel.log
journalctl -b -1 --no-pager | egrep -i "reboot|shutdown|panic|watchdog|oom|segfault|error" > /tmp/boot_minus1_keywords.log
systemctl list-timers --all > /tmp/timers_all.log
4)把证据包打包
tar czvf /tmp/reboot_forensics_$(date +%F_%H%M).tar.gz /tmp/boot_minus1_*.log /tmp/timers_all.log
拿着这个包,你可以:
给厂商/系统组复盘
走审计/问题单
准确定位是“任务”还是“崩溃”
七、最常见“每 2 小时重启”的前 6 名根因(经验排序)
cron / systemd timer 写了 reboot(最常见)
运维平台/基线 agent 定时修复策略
watchdog 超时触发重启(死锁/驱动问题)
内核 panic(驱动/存储/网卡/内核 bug)
BMC 过温/电源抖动导致硬复位
虚拟化平台 HA/健康检查重启 VM
你只要按上面流程走,基本一定能命中其中之一。
八、你下一步该怎么做(最短路径)
你把下面 4 段输出贴我(不用脱敏到太细,IP/主机名可打码),我就能直接告诉你属于哪一类:
1)
last -x | head -n 30
2)
journalctl --list-boots
3)
journalctl -b -1 -n 200 --no-pager
4)
systemctl list-timers --all
只要这四段,基本就能把“每两小时重启”从猜测变成定性结论。