

Trigger ≠ 阈值,Trigger 是把“数据”变成“行动”的那一步
一、Trigger ≠ 阈值:这是 90% 人的第一个认知误区
很多人理解的 Trigger 是:
CPU > 80% 就报警
磁盘 < 20% 就报警
这是错的。
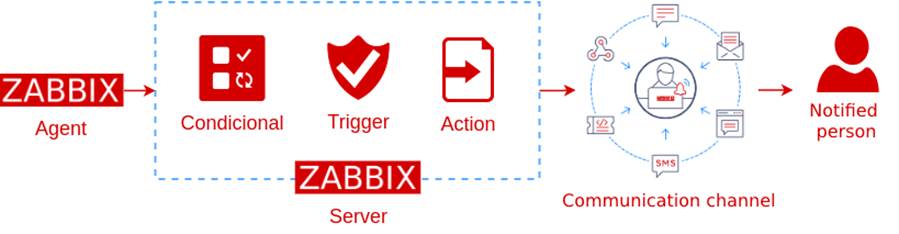
1️⃣ Item 负责“测量”,Trigger 负责“判断”
Item:采集数据(事实)
Trigger:判断是否异常(逻辑)
Action:异常之后做什么(响应)
👉 Trigger 本质上是一个判断表达式,不是一个数值。
2️⃣ 阈值只是 Trigger 的“原材料”
举个直观例子:
❌ 错误做法:
CPU 使用率 > 80% 报警
✅ 正确思路:
CPU 在一段时间内持续处于高位,且趋势异常
你要判断的不是“有没有超过线”,而是:
是否持续
是否影响业务
是否需要人介入
二、常见 Trigger 表达式拆解
下面是 Zabbix 里最核心、最常用的三类函数。
1️⃣ last() —— 最近一次值(最危险,也最常被保证)
last(/Linux/agent.cpu.util[,system]) > 80含义:
最近一次采集的 CPU system 使用率 > 80%
⚠️ 问题在哪?
只看一个点
非常容易被瞬时抖动触发
是“报警风暴”的根源之一
📌 结论:last() 只能用于状态型指标(如端口 up/down),
不适合性能指标。
2️⃣ avg() —— 时间窗口平均值(最常用)
avg(/Linux/agent.cpu.util[,system],5m) > 80含义:
最近 5 分钟内,CPU system 使用率的平均值 > 80%
适用场景
CPU
内存
网络带宽
IO 利用率
📌 经验值:
性能类指标:avg() + 时间窗口
时间窗口通常 ≥ 3 × 采集间隔
3️⃣ count() —— 发生次数(高手常用)
count(/Linux/net.if.in[eth0],5m,"gt",100000000) >= 3含义:
5 分钟内,有 ≥3 次流量超过阈值
这个函数解决什么问题?
避免一次“尖峰”就报警
判断异常是否反复出现
📌 典型用法:
网络突发
丢包
连接数暴涨
三、抖动 & 瞬时异常,应该怎么处理?
这是 Trigger 设计的分水岭问题。
场景 1:CPU 突然 100%,5 秒后恢复
你想要的是?
❌ 立刻报警
✅ 只有持续异常才报警
正确 Trigger 示例
avg(/Linux/agent.cpu.util[,system],5m) > 85而不是:
last(...) > 85场景 2:网络偶发丢 1 个包
count(/Linux/net.tcp.service[http],3m,"eq",0) >= 2含义:
3 分钟内,有 2 次服务不可达才报警
场景 3:磁盘写满是“渐进式灾难”
磁盘最怕的是没有提前预警。
推荐双 Trigger 设计:
⚠️ 预警
last(/Linux/vfs.fs.size[/,pused]) > 80🔥 严重
last(/Linux/vfs.fs.size[/,pused]) > 90📌 这叫分级告警,不是“一个阈值打天下”。
四、避免“报警风暴”的 5 个工程化技巧
这一部分,决定你的 Zabbix 是“生产力工具”还是“噪音制造机”。
✅ 技巧 1:一个 Trigger,只解决一个问题
❌ 错误:
一个 Trigger 同时判断 CPU + IO + Load
✅ 正确:
CPU 一个
IO 一个
Load 一个
✅ 技巧 2:尽量使用时间窗口函数
优先级推荐:
avg() > count() > last()✅ 技巧 3:用 Severity 分层,而不是全是 Disaster
建议企业级分级:
📌 不是所有报警都值得半夜叫醒人。
✅ 技巧 4:合理使用 OK event generation
开启:
Recovery expression(恢复条件)
避免“反复报警/恢复/报警”
✅ 技巧 5:Trigger 要和 业务场景 绑定
问自己一个问题:
这个报警响了,我要不要立刻处理?
如果 不用 → 不该报警
如果 必须 → Trigger 设计还不够好
五、Trigger 的终极判断标准
一个 Trigger 是否优秀,不看表达式多复杂,只看一件事:
它是否能在“正确的时间”,提醒“正确的人”,处理“正确的问题”
本讲价值总结
通过这一讲,你应该真正意识到:
Trigger 不是阈值
Trigger 是判断逻辑
好的 Trigger = 少而准
报警设计,本质是运维工程能力
不是没监控,而是报警没用。
而从这一讲开始,你已经知道怎么让它“有用”。