
如果你觉得 Zabbix 的工作是:
装 Agent
点“创建监控项”
看图表
那你大概率会在半年后被自己骂一句:
“这监控系统根本没法维护。”
这一讲,我们彻底把 Item 这件事讲透。
一、Item 的本质到底是什么?
我们先说一句“反直觉但正确”的话:
👉 Item 不是“监控指标”
👉 Item 是“一次被系统调度的采集任务定义”
拆开看,Item 至少包含 6 个核心要素:
一句话总结:
Item = 采集逻辑 + 调度策略 + 生命周期设计
所以——
Item 从来不是“随便点一个就完事”的东西。
二、常见 Item 类型一次讲透
下面这几种,是你在真实企业环境中一定会用到的。
1️⃣ Zabbix agent(被动)
工作模型:
Server / Proxy → Agent → 返回数据
特点:
简单直观
强依赖网络可达
Server 压力集中
典型场景:
小规模内网
基础 OS 指标
典型 Item Key:
system.cpu.util
vfs.fs.size[/,used]⚠ 被动 Item 多了,Server 一定会慢
2️⃣ Zabbix agent (active)(推荐)
工作模型:
Agent → 主动拉配置 → 执行 Item → 推送数据优势极其明显:
Server 不再主动 Poll
天生适合大规模
容错性更强
工程结论:
📌 只要条件允许,Agent 类 Item 一律 Active
3️⃣ Zabbix trapper(被很多人误用)
这是一个“被动接收数据”的 Item 类型。
它不采集,只接收:
应用主动推送
脚本异步上报
日志系统对接
典型使用场景:
业务系统主动上报状态
批处理 / 异步任务结果
无法 Poll 的系统
zabbix_sender -z server -s host -k key -o value❗ Trapper 不会自己产生数据
你建了 Item,但没人推 = 永远没值
4️⃣ SNMP(企业网络设备的主力)
SNMP Item 的核心不是“会不会配”
而是:
你有没有能力管理 OID 生命周期
SNMP 的真实难点:
OID 语义不可读
设备厂商差异极大
版本 / MIB 维护成本高
工程建议:
SNMP 必须模板化
禁止 Host 级散配 OID
禁止临时加 OID 不归档
5️⃣ External check(最后的手段)
本质:
Server 上执行脚本
非 Agent、非 SNMP
为什么要谨慎?
阻塞 Server
不可控执行时间
难排障、难审计
工程结论:
❌ 能 Agent,不用 External
❌ 能 Proxy,不直接 Server 执行
三、Item 命名规范(企业级,不是“好看”)
你今天随便起的名字,半年后一定会害你。
❌ 新手常见命名
CPU使用率
磁盘占用
内存监控问题:
没层级
没语义
搜索困难
自动化不可能
✅ 企业级命名规范示例
os.cpu.util.avg
os.mem.used.percent
fs.root.space.used
net.eth0.in.bps
设计原则:
1️⃣ 对象在前,指标在后
2️⃣ 层级结构 ≤ 4 级
3️⃣ 英文 + 语义稳定
4️⃣ 禁止夹带展示信息
📌 Item Name 是给人看的
📌 Item Key 是给系统用的
两者必须分离设计
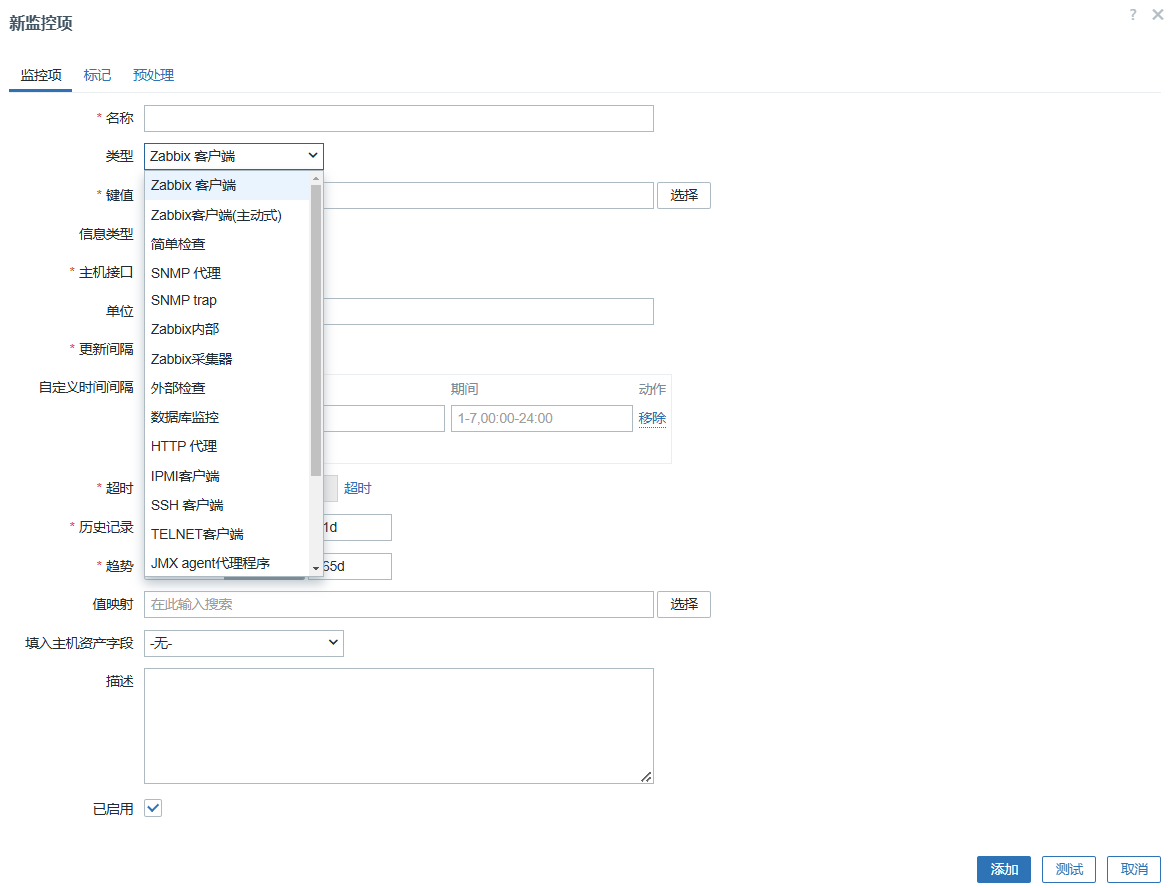
四、为什么你建的 Item 后期维护成本极高?
这是很多 Zabbix 系统 “活着但不可维护” 的根本原因。
① Item 没有分层设计
OS
Middleware
App
Business
全部混在一个 Host 里。
② Item 不可复用
不用模板
每台主机单独建
改一次要改 100 次
③ Item 和告警强耦合
一个 Item 绑一个 Trigger
修改阈值牵一发而动全身
④ 采集频率无规划
📉 你不是在“精细监控”
👉 你是在 慢性自杀
五、真正专业的 Item 设计思路
记住这套“设计顺序”,你就入门了:
1️⃣ 先想:我要解决什么运维问题?
2️⃣ 再想:这个问题是否值得长期监控?
3️⃣ 再决定:采集方式(Agent / SNMP / Trapper)
4️⃣ 再设计:采集频率 & 保存策略
5️⃣ 最后才是:点鼠标建 Item

六、本讲你真正该带走的 5 个认知
1️⃣ Item 是设计产物,不是配置动作
2️⃣ Item 决定了系统的可维护性上限
3️⃣ 不会设计 Item,就谈不上会 Zabbix
4️⃣ 模板不是偷懒,是工程能力
5️⃣ 监控系统 ≠ 数据越多越好
本讲价值总结
这一讲真正想让你意识到一句话:
“监控不是点点鼠标,而是设计工作。”
当你开始用“设计”的视角看 Item:
你会天然排斥垃圾指标
你会开始关心长期维护成本
你会真正具备 监控架构师的思维