“明明想保存一份网页手册或在线文档,但它全是前端渲染的 JS 页面,滚动加载、动态拼 DOM、禁止复制打印……怎么导出成干净的 PDF?”
导语:
你是不是也遇到过这种网页:
看似是一个在线手册、说明书、产品教程,但当你想保存为 PDF 时才发现——
页面是前端 JS 动态渲染的,滚动才加载内容,甚至右键都被禁用。
米家、小米、华为、Apple Developer、某某 API 文档站……
看得到、点得动、但保存不了。
今天,我们就来深入讲讲:
💡 如何把这种“纯前端、动态加载的网页”
精准、完整、格式不乱地,做成一份可离线保存的 PDF 手册。
一、为什么这些网页“保存不了”
传统网页(HTML + CSS)是静态加载的,浏览器打开后内容就在 DOM 里。
但现在大多数现代文档网站都改用了 SPA(Single Page Application) 架构:
使用 Vue、React、Angular 等框架渲染;
内容在前端通过 JavaScript 异步请求(AJAX / fetch / GraphQL) 获取;
页面滚动时动态注入 DOM(懒加载);
经常加入防复制、防打印脚本。
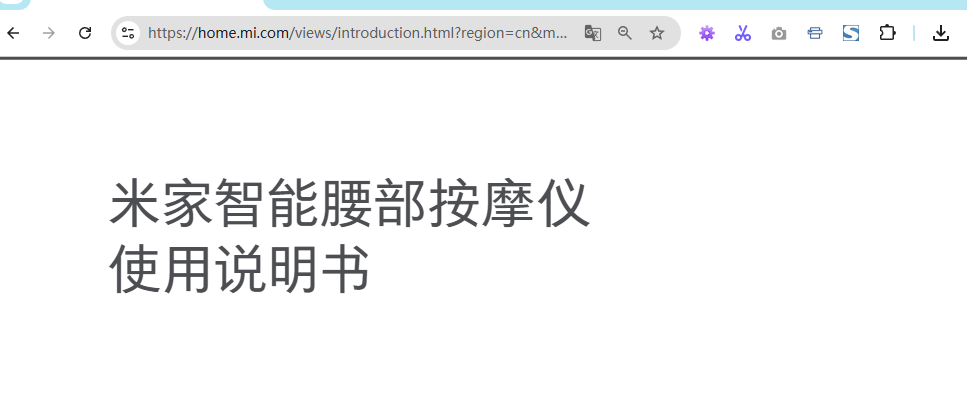
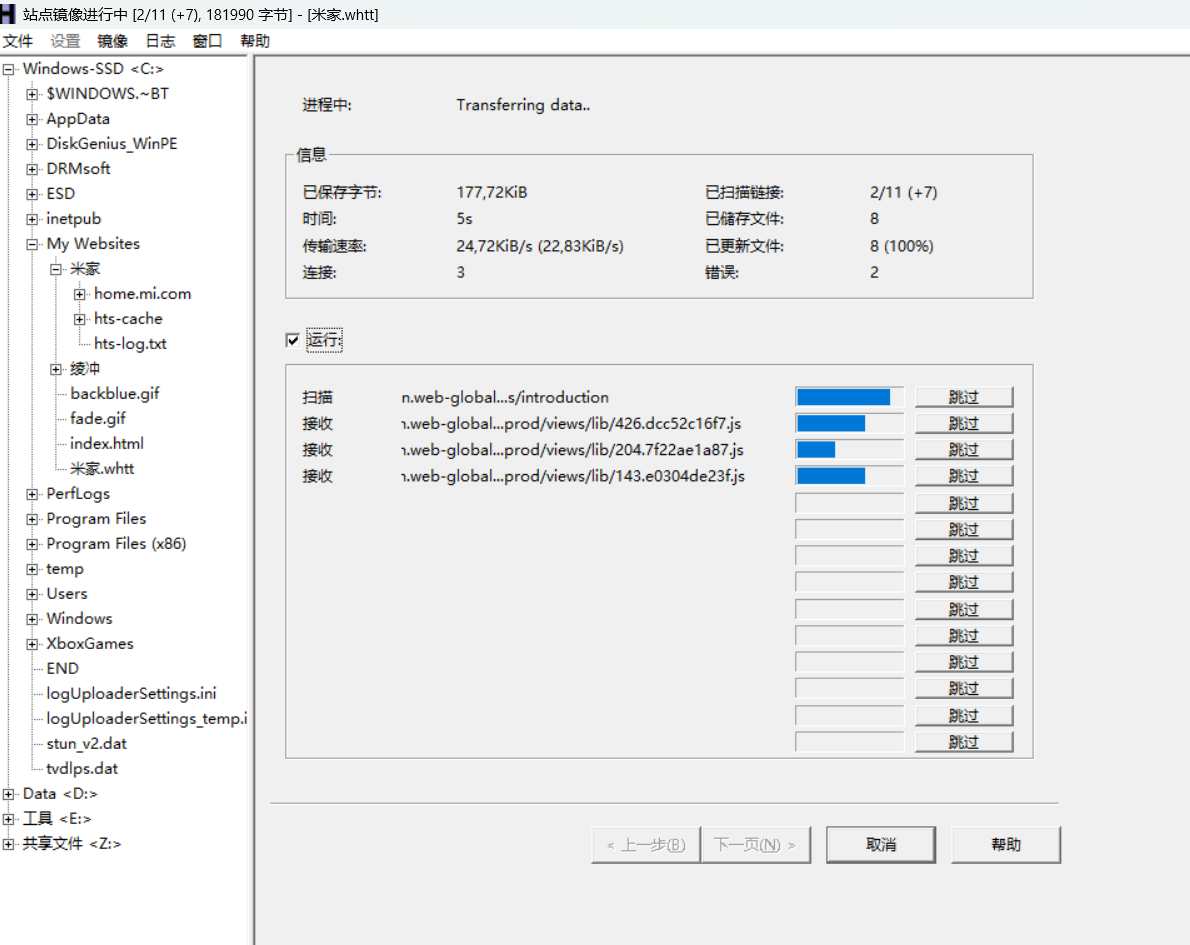
📌 举个典型例子——“米家设备手册网页版”:
网页主体结构为空壳;
实际内容是通过 JS 请求接口再拼接生成;
Ctrl+P 打印时,只能截到首屏,下面全空白;
HTML 源码里找不到正文。
https://home.mi.com/views/introduction.html?region=cn&model=xiaomi.magic_touch.yb01
二、常规方法为什么失效?
🔴 结论:
JS渲染的SPA网页,必须“让浏览器先执行完所有脚本,再转为PDF”。
否则永远只会得到半张白纸。
三、核心思路:让网页“自己渲染完再导出”
我们需要让网页完全加载、等待JS执行完毕、滚动触发懒加载、再渲染为PDF。
这就要用到——浏览器自动化与PDF引擎。
四、方法一:用 Puppeteer 全自动生成PDF(专业推荐)
Puppeteer 是 Google 官方维护的 Node.js 库,用来控制无头 Chrome 浏览器。
它能:
加载网页;
等待 JS 渲染;
执行滚动加载;
最后导出完整 PDF。
安装
npm install puppeteer脚本示例
const puppeteer = require('puppeteer');
(async () => {
const url = 'https://miot-specs.readthedocs.io/zh/latest/'; // 示例:米家设备手册
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle2', timeout: 0 });
// 自动滚动加载全部内容
await autoScroll(page);
// 导出 PDF
await page.pdf({
path: 'mi-home-manual.pdf',
format: 'A4',
printBackground: true
});
await browser.close();
})();
// 自动滚动函数
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
let totalHeight = 0;
const distance = 500;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if(totalHeight >= scrollHeight){
clearInterval(timer);
resolve();
}
}, 300);
});
});
}
✅ 特点:
自动执行JS渲染;
自动滚动触发懒加载;
可生成高清PDF;
支持页眉、页脚、自定义纸张。
📦 适合场景:
想保存一整个说明书网站、API文档、在线手册、知识星球课程网页合集等。
五、方法二:使用 Chrome DevTools + 完整截图
适合不写代码的用户。
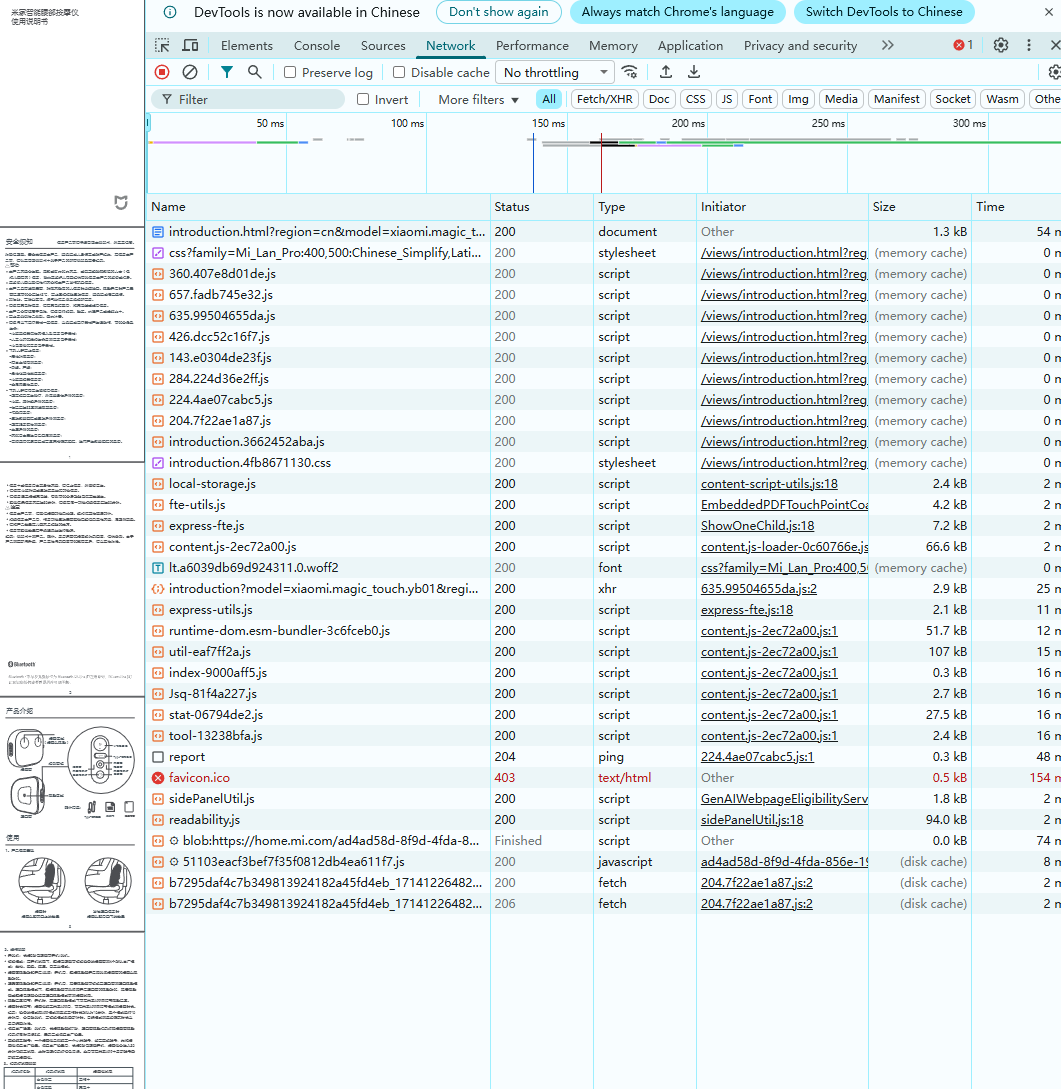
1️⃣ 打开网页 → 按 F12 打开开发者工具
2️⃣ 切换到 “Network” 面板
3️⃣ 滚动网页,确保内容全部加载完毕
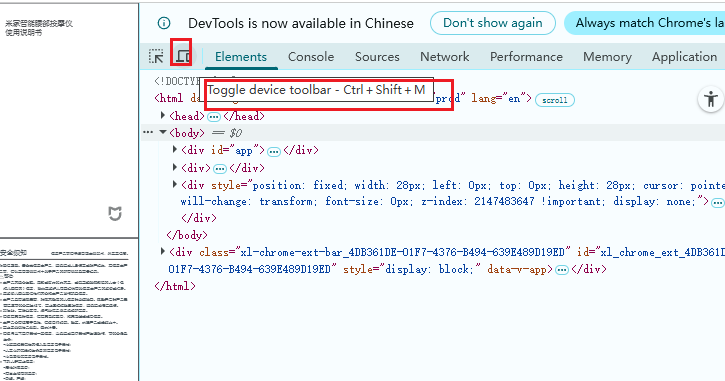
4️⃣ 切换到 “Device Toolbar”(手机/平板模式)
5️⃣ 在右上角三点菜单选择:
Capture full size screenshot(捕获整页截图)
6️⃣ 得到完整 PNG → 用 Acrobat 或 SmallPDF 转 PDF
🟢 优点:
不用写脚本
能捕获完整渲染页面
🔴 缺点:
只能图片式PDF,不可搜索文字
页面过长时容易内存超限
六、方法三:用 Playwright(更强的多浏览器自动化)
Playwright 是 Puppeteer 的升级版,支持 Chrome、Firefox、WebKit,性能更稳。
示例
npm install playwright
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://miot-specs.readthedocs.io/zh/latest/', { waitUntil: 'networkidle' });
// 滚动加载
await page.evaluate(async () => {
for (let i = 0; i < 20; i++) {
window.scrollBy(0, window.innerHeight);
await new Promise(r => setTimeout(r, 200));
}
});
await page.pdf({ path: 'manual.pdf', format: 'A4', printBackground: true });
await browser.close();
})();
七、方法四:终极解决方案——爬取后重构HTML导出
如果你想归档整个文档站,可以:
1️⃣ 用 wget 或 httrack 把整个网站离线镜像下载;
2️⃣ 用 wkhtmltopdf 或 pdfkit 批量将离线HTML转为PDF。
wget -r -np -k https://miot-specs.readthedocs.io/
wkhtmltopdf index.html output.pdf
🧩 这样做适合长期保存技术文档,如:
Vue / React / Docker / KylinOS 官方手册
国企安全测评系统说明书
内部开发API文档
httrack网站离线下载器
八、专业建议与心得
别直接Ctrl+P保存SPA网页。那只是截图,不是归档。
Puppeteer 是黄金方案:能执行JS、滚动加载、渲染样式。
若PDF太大,可拆分章节导出。
加参数:
await page.pdf({scale: 0.9, margin: {top: '20mm'}});可以优化视觉效果。
九、写在最后:保存的不是网页,是知识的可控性
技术世界在前端化、动态化,我们看到的内容越来越“云端”,而非文件。
当我们用一段脚本,让一个网页重新“落地成PDF”,
其实做的不是存档,而是让知识重新可控、可分享、可传承。
这份教程,不只是“怎么保存网页”,
更是“在前端时代,如何保存自己的世界”。
十:结尾彩蛋:
网页转PDF工具(适合页面较少,自动截取全屏的傻瓜插件)
登录Google应用商店
https://chromewebstore.google.com/category/extensions
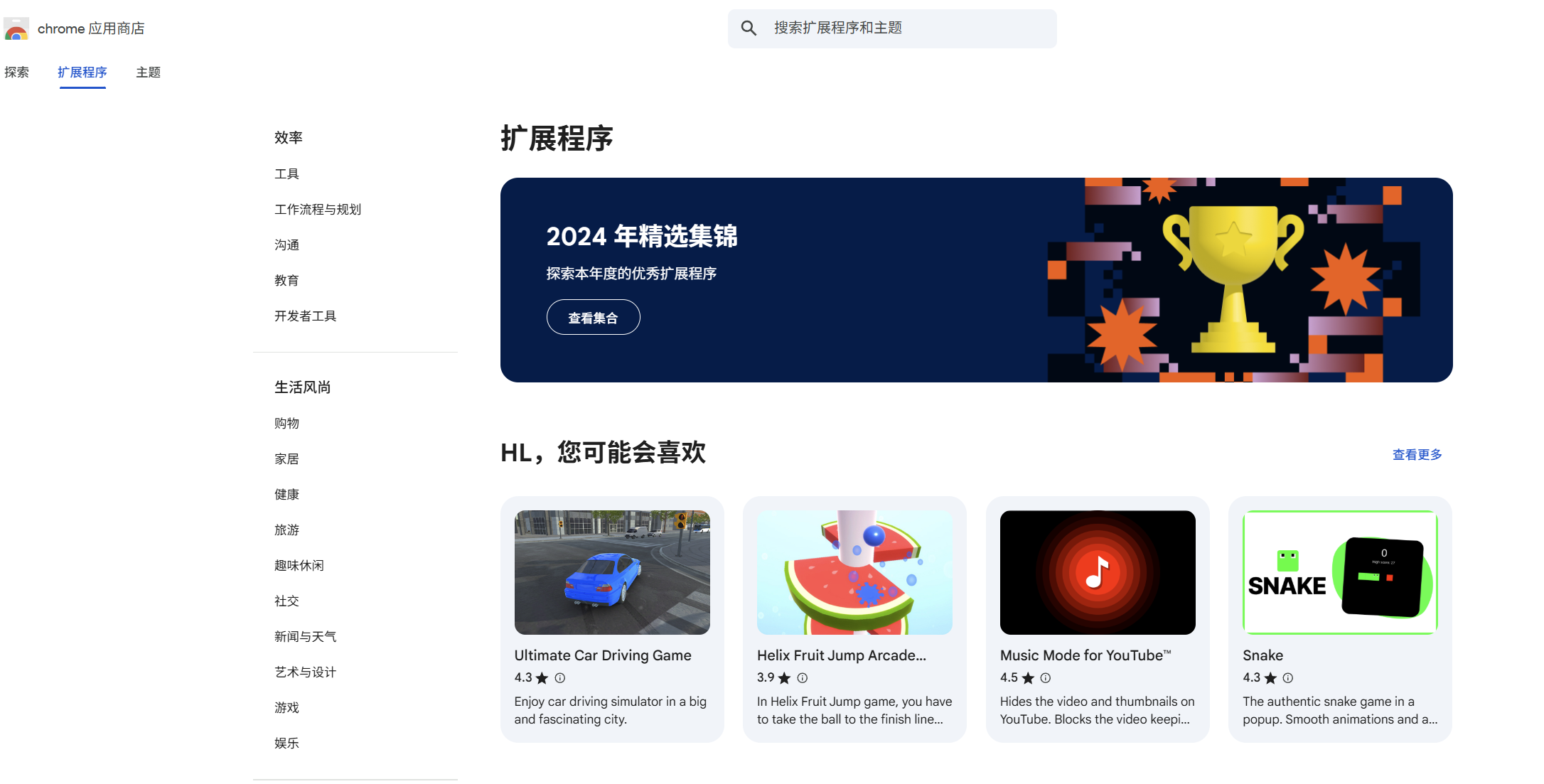
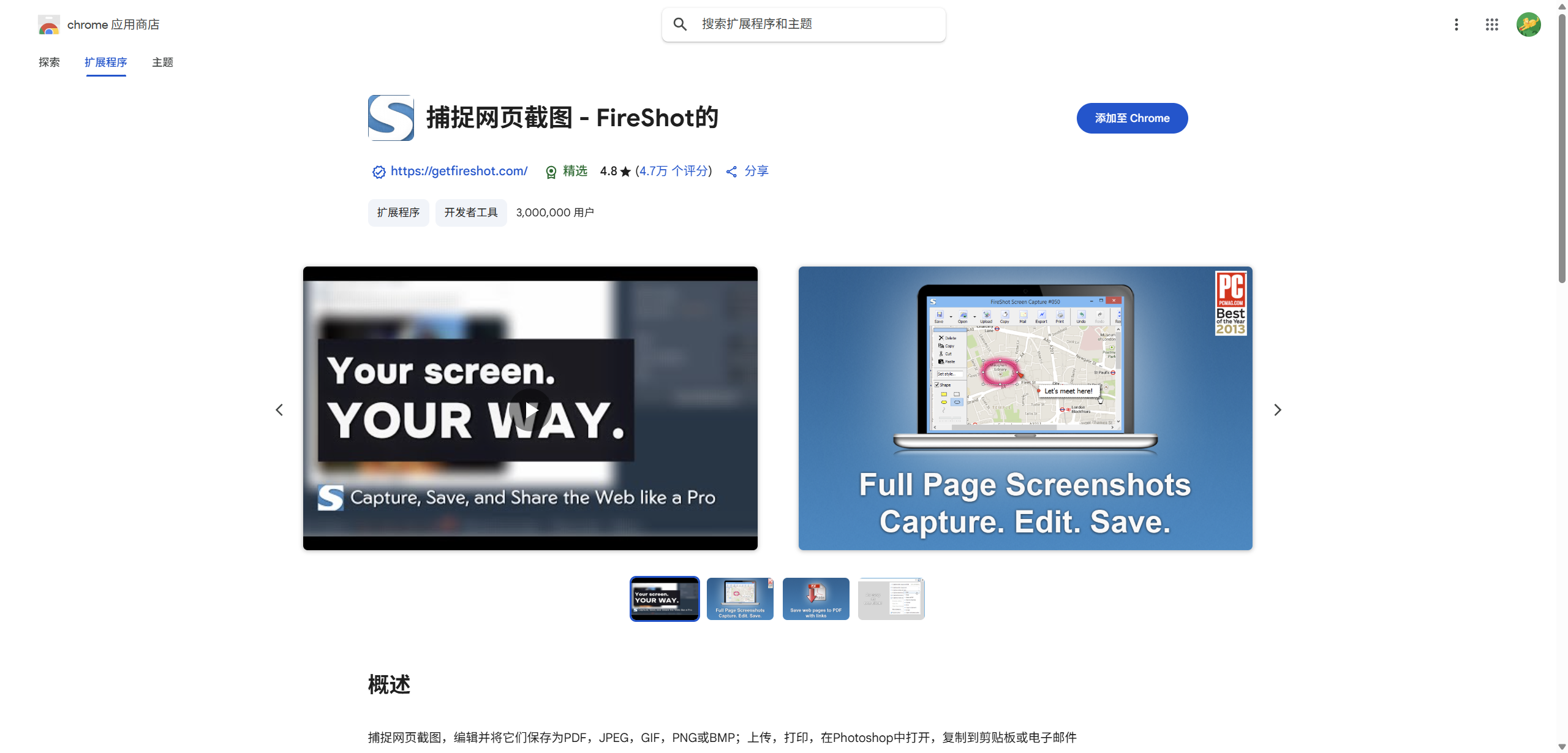
搜索FireShot插件并安装
打开想要转化为PDF的网页并点击启动插件
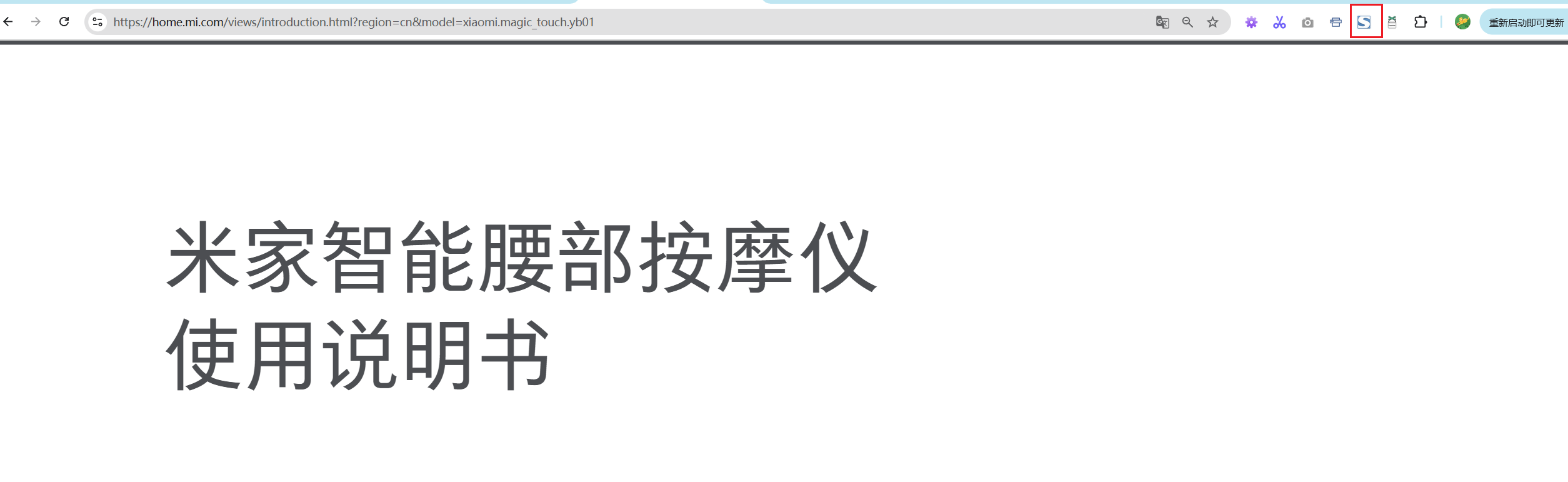
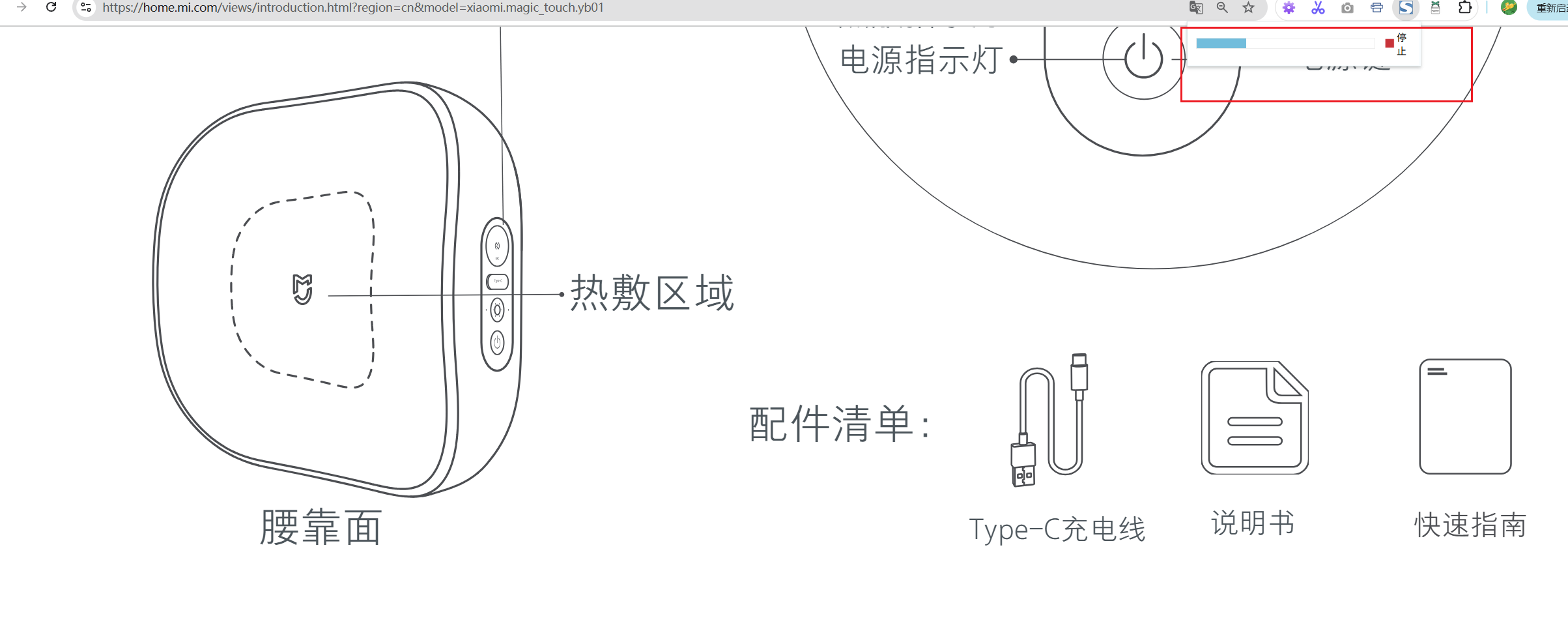
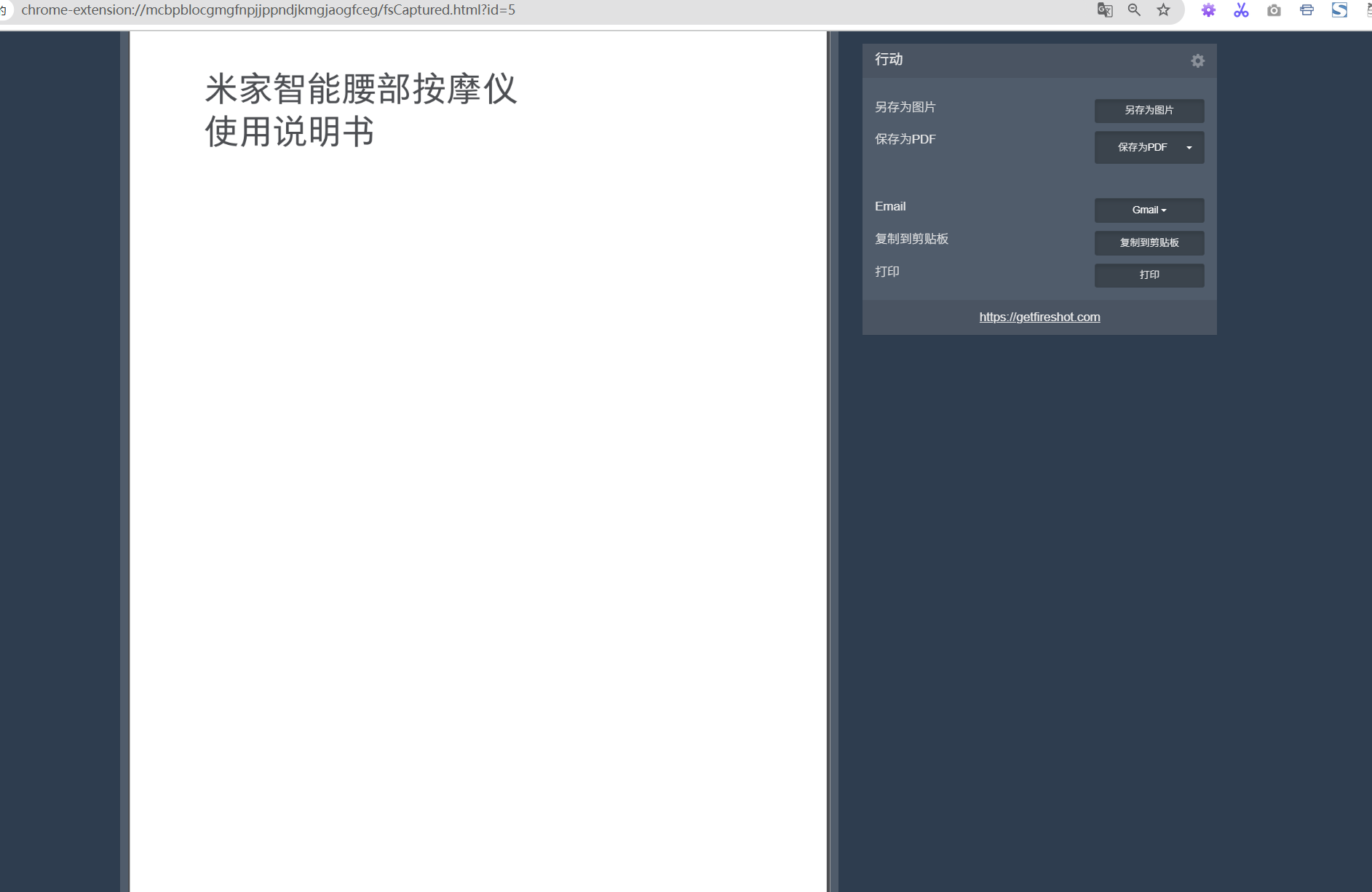
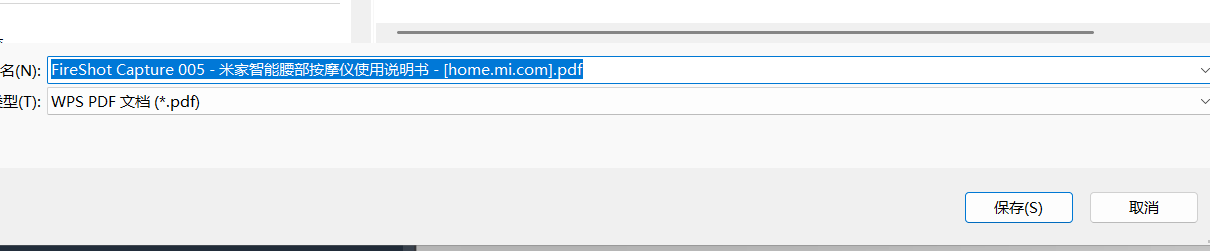
点击保存如下所示
如果页面较多,可以选择安装高级版
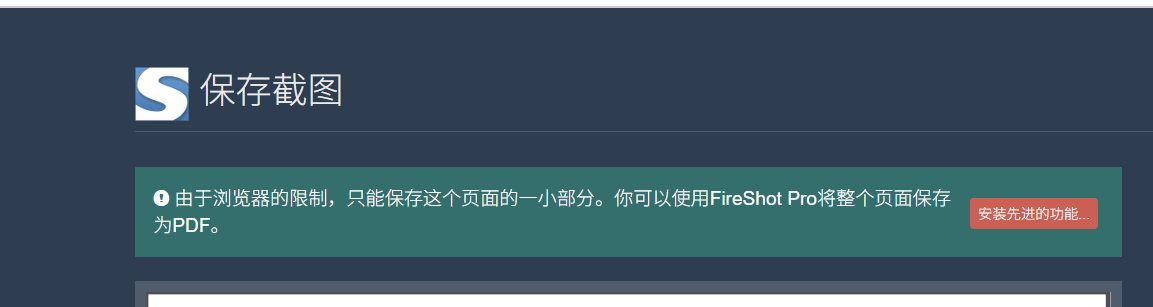
高级版安装
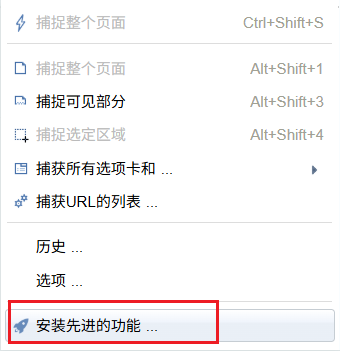
安装成功后如下所示
生成的PDF如下所示,无错页和格式错误
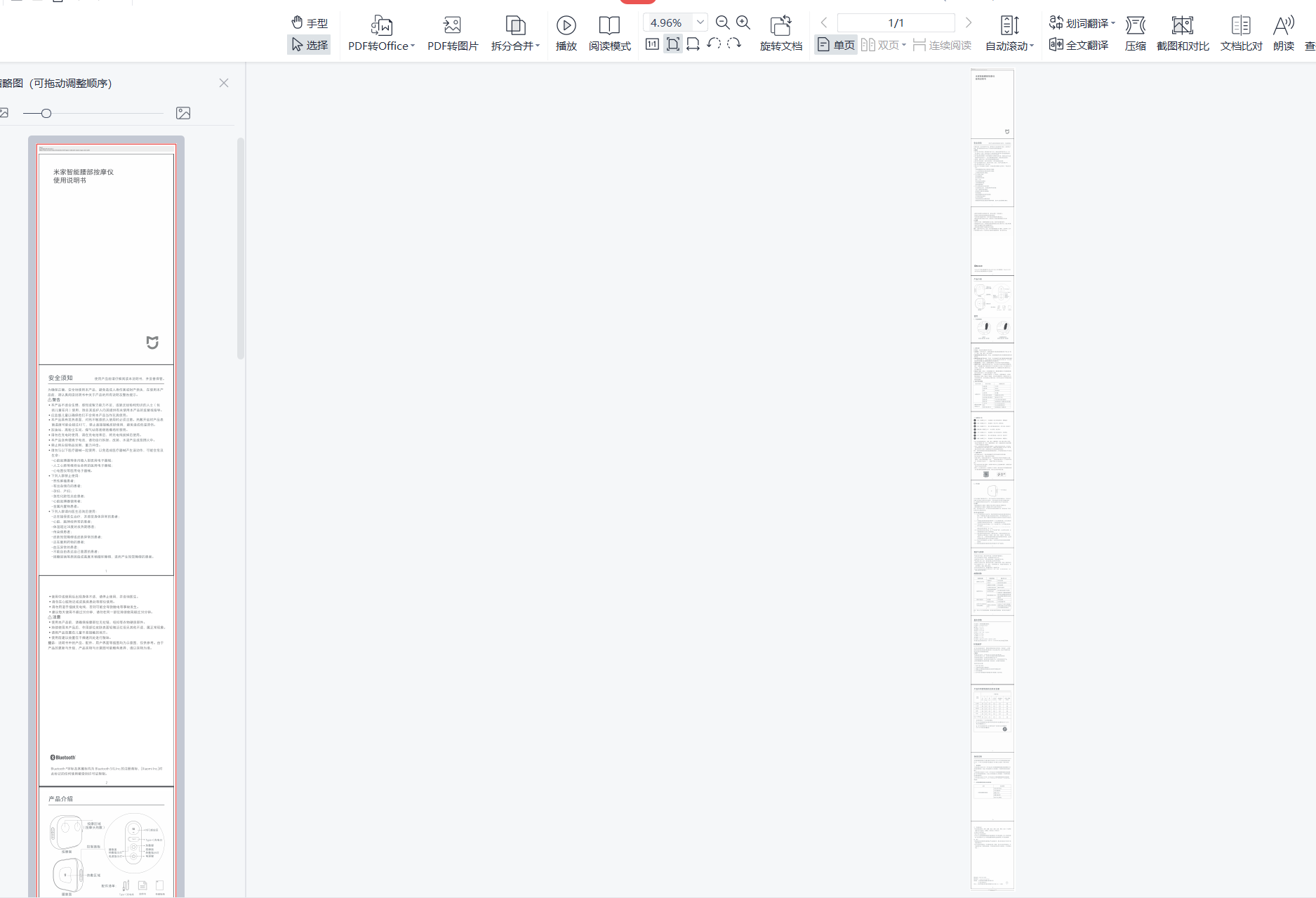
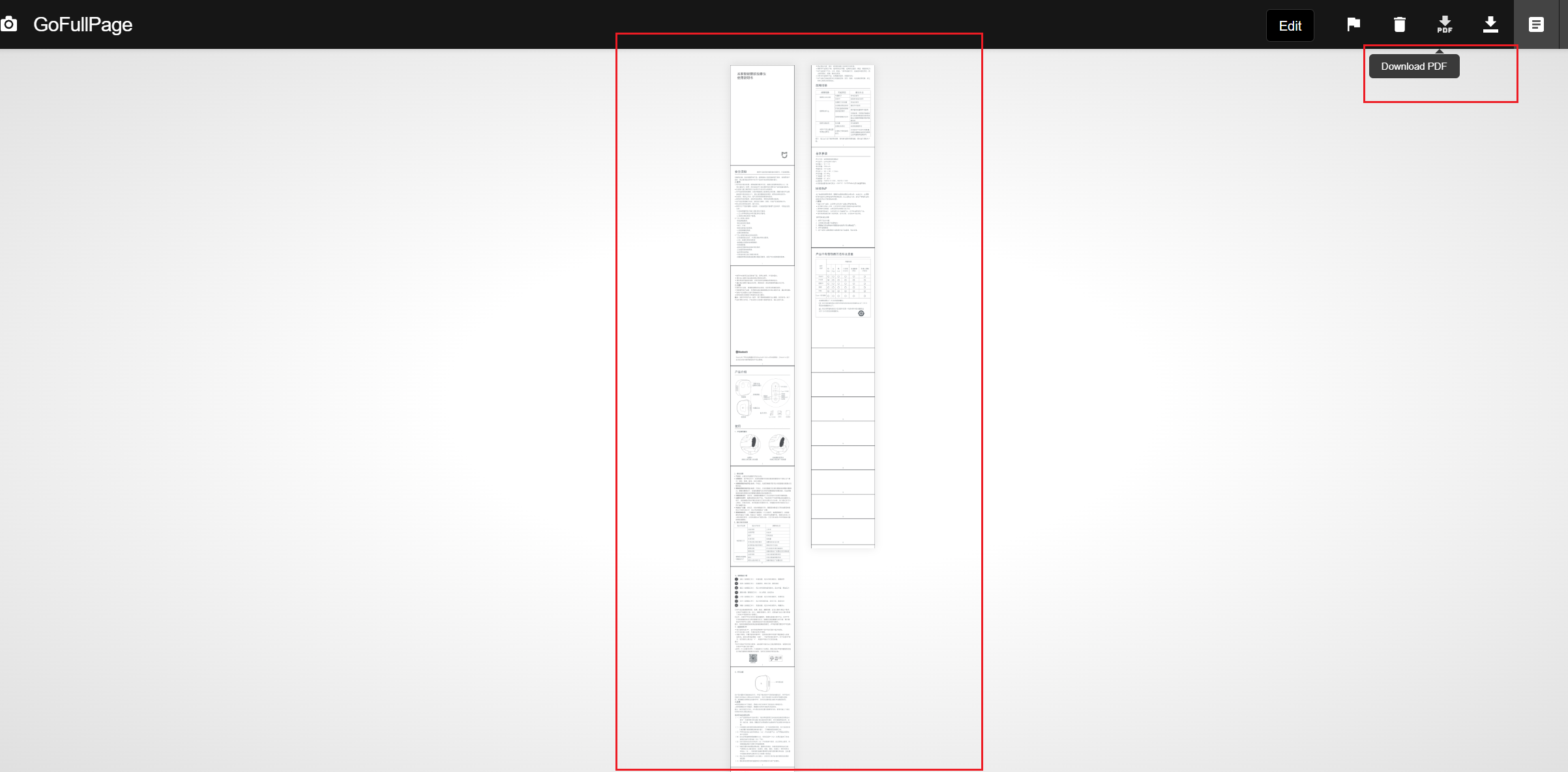
不建议的插件-GoFullPage - Full Page Screen Capture
固定扩展程序到任务栏
选取网页并点击自动生成如下内容
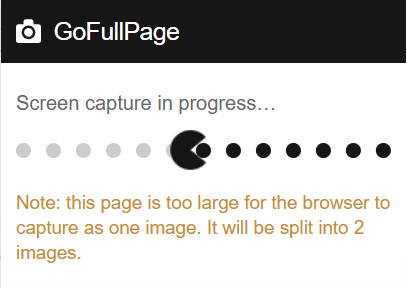
下载转换好的PDF,可以发现错了很多错页