
一、背景需求
在企业一些场景中,需要去监控一些外部网站或者ip的网络联通性。
比如说:某个第三方业务网站-财务的某系统,经常使用,又是在外网云服务器,如果断线了会影响到公司的业务。
需要一个实时又简单的监控,这个时候就可以使用ping监控来模拟,在配置zabbix的监控平台上面做。
1.1、需求设计:
1.不想在服务器安装zabbix客户端,或者无法安装zabbix客户端,只是想做简单的IP地址ping测试
2.需要监控外部DNS或者出口IP地址,实时发现网络是否断开
3.需要监控业务系统,例如CRM系统,ERP系统,财务系统等的IP地址,实时发现网络是否保错
4.需要监控公司官网地址或者其他IP地址,实时发现网络是否断开
5.上诉需求,服务端已在防火墙开通ICMP-ping协议,平时在自己电脑测试过,可以ping通
1.2、很多人第一次做 Zabbix 时,会把监控对象简单分成两类:
能装 Agent 的 → 用 Agent
能开 SNMP 的 → 用 SNMP
但真正的企业环境里,经常会出现第三类:你谁都用不了。
典型场景
设备不允许安装软件(第三方厂商设备、封闭系统、工控设备、涉密终端)
SNMP 被禁用或跨域不可达(安全域隔离、跨网单向、策略不放行)
只允许“极少量探测”,连 TCP 端口都不能扫
你甚至只有一个 IP 地址,其他信息全无
这类资产如果不纳入监控,结果就是:
“出了问题你最后一个知道,追责时你第一个挨骂。”
而最通用、最不冒犯安全策略、最容易被放行的,就是:ICMP Ping。
二、为什么 Zabbix “Ping”也常常做不好?
你可能已经发现:
有时候你在 Zabbix 里给主机加了 “ICMP Ping”,但还是:
没数据、一直 Unsupported
有数据但丢包率不准
图形画不出来
告警要么太敏感(抖一下就炸),要么太迟钝(真挂了不报警)
原因通常就三类:
Ping 的执行点搞错了(应该由 Server/Proxy 去 Ping,而不是 Agent)
监控项类型/键值没选对(icmpping / icmppingloss / icmppingsec)
触发器逻辑不专业(没有用趋势/次数、没有区分抖动与故障)
这篇文章就按“生产可用”的标准,把这件事完整做一遍。
三、前置检查:Ping 是谁来执行的?
结论
ICMP Ping 是由 Zabbix Server 或 Zabbix Proxy 来执行的
你的“监控盲区主机”不需要装 Agent,也不需要 SNMP
你必须确认的 2 个条件
Server/Proxy 能 Ping 到目标 IP
Server/Proxy 所在网络安全策略允许发 ICMP(有些单位默认禁 ICMP)
建议你在 Zabbix Server/Proxy 容器/主机上先手工验证:
ping -c 4 目标IP
如果这里 ping 不通,Zabbix 再怎么配都不会出数据。
四、手工添加 Ping 监控(从 0 到 1)
下面以“你已经创建了一个主机(Host),但没有 Agent/SNMP”的情况为例。
Step 1:创建主机(Host)
路径:Configuration → Hosts → Create host
关键点:
Host name:建议用规范命名(例如
IDC-AZ1-DB-01)Interfaces:
如果你不用 Aent Interface 的 IP(不一定用得上,方便识别)
Groups:放入一个专门的组
例如:
NoAgent_NoSNMP、Ping-Only
保存。
五、三条监控项:在线、延迟、丢包
生产标准:Ping 监控必须至少包含这三项
可达性(在线/离线)
时延(latency)
丢包率(lossHost → Item:ICMP 可达性(在线状态)
监控项 1:ICMP 可达性(在线状态)
Name:
ICMP ping availabilityType:
Simple checkKey:
icmppingUpdate interval:
30s(生产常用 30s 或 1m)History storage period:
7d(按需)Trends storage period:
365d(按需)
含义:
返回
1表示可达返回
0表示不可达
监控项 2:ICMP 丢包率
Name:
ICMP ping lossType:
Simple checkKey:
icmppinglossUnits:
%Update interval:
30s
含义:返回 0~100(%)
监控项 3:ICMP 延迟(响应时间)
Name:
ICMP ping response timeType:
Simple checkKey:
icmppingsecUnits:
s(秒)Update interval:
30s
你也可以把单位改成 ms(毫秒)显示更直观:
Zabbix 默认 key 是秒,图表里可以通过乘 1000(预处理)实现,但为了易维护,本文以默认秒为准。
六、让图形“一眼看懂”:延迟 + 丢包联合图
路径:Host → Graphs → Create graph
图形 1:Ping 延迟趋势图
Name:
ICMP latencyAdd item:
ICMP ping response timeY 轴:自动即可(或手动设置)
图形 2:丢包率趋势图
Name:
ICMP lossAdd item:
ICMP ping lossY 轴建议:0~100
图形 3:延迟+丢包合一图
Name:
ICMP quality (latency + loss)Add item:
ICMP ping response timeICMP ping loss
如果版本支持双 Y 轴就用双轴(loss 用 0~100,time 用秒)
目的:
当用户反馈“卡”,你能第一时间判断是:
丢包导致重传(loss 上升)
延迟飙升(time 上升)
还是直接掉线(availability=0)
七、触发器(Trigger)才是真正“付费级”的地方
很多人告警做不好,是因为触发器逻辑太“幼儿园”:
icmpping=0就报警
结果:网络抖一下,告警风暴。
下面给你一组“企业常用、抗抖动、能分级”的触发器方案。
路径:Host → Triggers → Create trigger
触发器 1:主机不可达(硬故障)
目标:真正掉线才报警,不被抖动误伤。
表达式(思路):
最近 5 次采样都为 0 才算离线
如果你是 30s 采样,相当于 持续 2~3 分钟不可达才告警。
示例(表达方式按你界面选择函数):
max(/<host>/icmpping,5m)=0
含义:过去 5 分钟最大值都是 0 → 持续不可达
Severity:High / Disaster(按你体系)
触发器 2:丢包率异常(网络质量差)
建议分两级:
2-1 丢包率 > 20% 持续 3 分钟(严重)
min(/<host>/icmppingloss,3m) > 20
Severity:High
2-2 丢包率 > 5% 持续 5 分钟(告警/预警)
min(/<host>/icmppingloss,5m) > 5
Severity:Warning / Average
为什么用 min?
因为我们要的是“持续异常”,不是某一个点尖峰。min确保这 5 分钟内每次都高于阈值,更抗抖。
触发器 3:延迟异常(拥塞/绕路/链路抖动)
同样分级:
3-1 延迟 > 0.2s(200ms)持续 5 分钟(预警)
min(/<host>/icmppingsec,5m) > 0.2
3-2 延迟 > 1s 持续 3 分钟(严重)
min(/<host>/icmppingsec,3m) > 1
延迟阈值怎么定?
同机房内:1~5ms(0.001~0.005s)
城域/跨园区:10~50ms(0.01~0.05s)
跨省/跨网:50~200ms(0.05~0.2s)
先用一周数据看基线,再定阈值最靠谱。
八、最容易被忽略的“关键细节”:Proxy 的作用
如果你的 Zabbix Server 不在能直达目标网络的位置,那么:
不要强行让 Server Ping
要用 Proxy 部署到离目标更近的网络域,然后由 Proxy 执行 Simple check
也就是说,Ping 的执行点要贴近目标网络,否则你监控的不是“主机质量”,而是“跨域链路质量”。
最佳实践:
每个安全域/机房放一个 Proxy
Proxy 就地 Ping、就地采集
汇总到 Server
这样你的告警才有意义:
目标主机掉线 vs 跨域链路断能分得清
九、常见故障排查清单(你会用得上)
1)监控项 Unsupported
Server/Proxy 无法 ping 目标(网络策略/路由/ACL)
容器里没权限发 ICMP(极少见,但某些安全策略会限制)
DNS/主机名解析问题(如果你填的不是 IP)
2)数据全是 0 或 100%
目标禁止 ICMP 或被限速
你监控的是网关/防火墙策略导致的假象
采样间隔太短导致抖动明显
3)告警风暴
触发器没做“持续时间/次数”判断
没分级,所有问题都按高危推送
十、详细操作举例
当你遇到“不能装 Agent / 不能 SNMP”的资产,统一执行:
Host 加入组:
Ping-Only3 个 Item:
icmpping / icmppingloss / icmppingsec2~3 张图:延迟、丢包、综合
触发器分级:
不可达(硬故障)
丢包(质量)
延迟(拥塞/绕路)
最终效果:
哪怕对方只给你一个 IP,你也能把它纳入告警闭环。
10.1、zabbix环境准备
Zabbix服务器 已配置好
一台客户端(windows/linux均可) 已添加进Zabbix客户端
需要监控的IP地址 已放通防火墙,客户端可以ping通
网络连通性 全通
10.2、添加监控项
(1)创建监控项
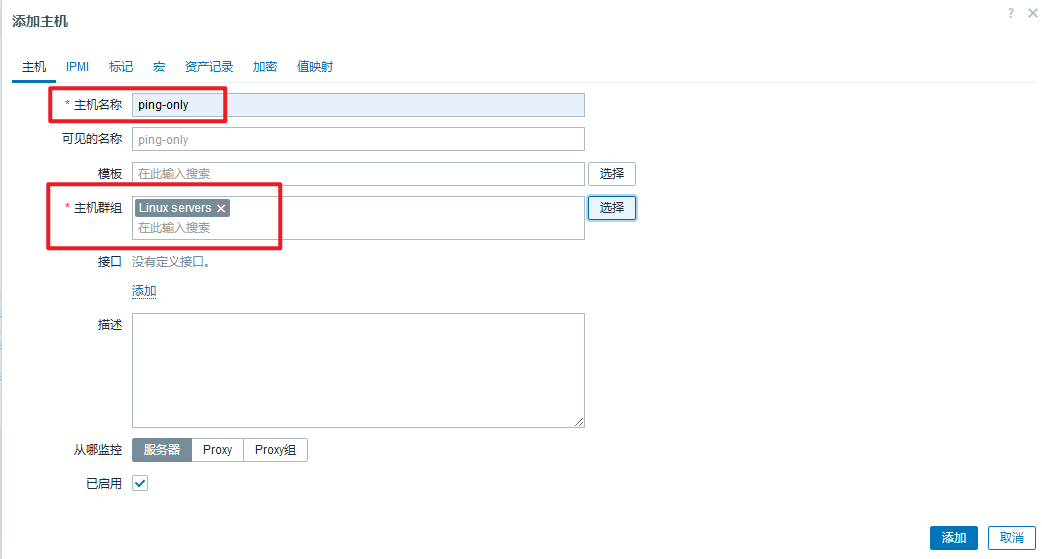
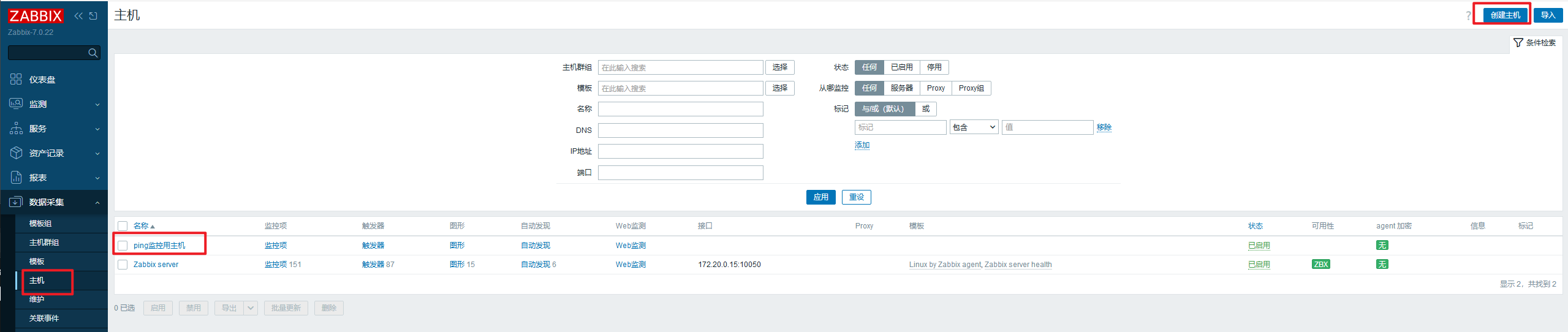
登陆后台,如果指定主机ping,那么选择任一台已经监控的Windows或者Linux客户端作为zabbix增加ping监控项的主机。
否则可以单独创建一个主机用于PING监控,点击【监控项】,去新增【创建监控项】
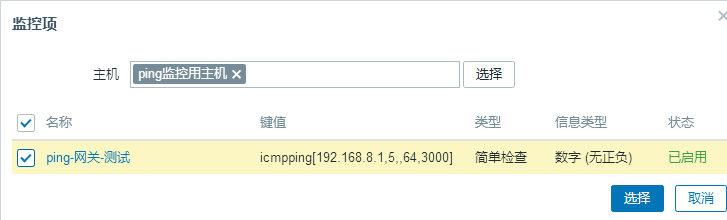
(2)配置监控项
点击右上角【创建监控项】,然后填写监控项的数据
名称:自己取一个
类型:简单检查
键值:icmpping[192.168.8.1,5,,64,3000]
主机接口:默认
信息类型:数字(无正负)
更新间隔:30s
历史数据保留时长:随便设置
趋势存储时间:随便设置
关于键值: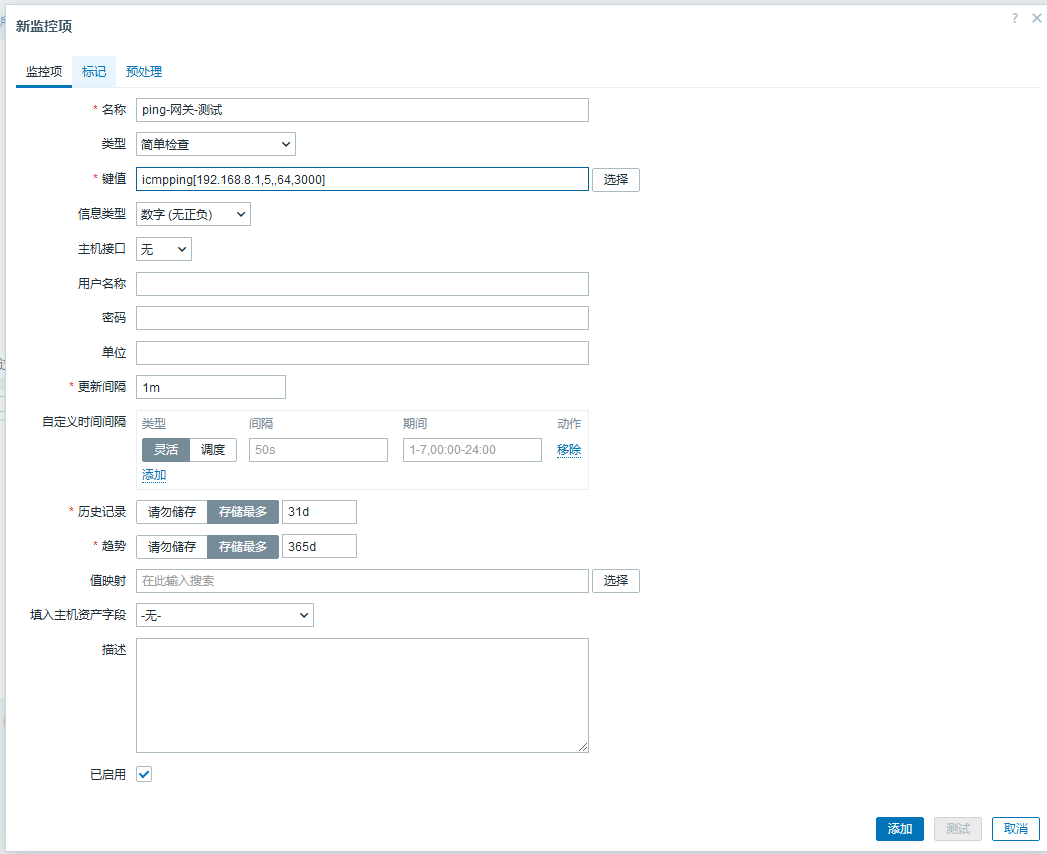
target:即你要ping的目标主机ip地址,直接写ip地址即可,无需双引号或单引号。
packets:每次发送的ping的包数量
interval:每次发送ping的间隔毫秒数。1000毫秒等于1秒
size:每个包的大小
timeout:等待超时的时间,单位也是毫秒
1️⃣ <target>:目标地址
192.168.8.1推荐做法
直接写 IP 地址
不推荐用域名(DNS 解析失败会被误判为网络不通)
原因
ICMP 监控的目标是“链路与可达性”
DNS 属于另一类监控问题
2️⃣ <packets>:每次探测的 ICMP 包数
✅ 推荐值:5
packets = 5原因说明
1包:对瞬时抖动极度敏感,容易误报3包:基本可用,但对不稳定链路仍偏敏感5包:工程实践中最常用,抗抖动明显提升>10包:监控开销增大,收益递减
👉 5 是“生产环境的甜点值”
3️⃣ <interval>:ICMP 包之间的间隔(毫秒)
✅ 推荐值:留空或 0
interval = (空)原因说明
让系统自行控制发包节奏
人为缩短 interval 容易:
形成 burst 流量
反而制造丢包假象
👉 99% 场景不需要手动设置
4️⃣ <size>:ICMP 数据负载大小(字节)
✅ 推荐值:64
size = 64原因说明
接近真实业务最小数据包
比“最小 ICMP”更贴近真实网络负载
不会触发 MTU / 分片问题
对比说明:
👉 64 是“认知成本最低”的选择
5️⃣ <timeout>:等待响应的超时时间(毫秒)
✅ 推荐值:3000
timeout = 3000原因说明
同机房通常 <1ms,但跨网不可预期
3000ms 能覆盖:
跨园区
VPN / 专线
短时拥塞
如果 timeout 太小:
网络通,但被误判为丢包
如果 timeout 太大:
告警滞后
👉 3000ms 是生产环境的通用安全值
6️⃣ <options>:额外 ping 参数
✅ 推荐做法:不填
options = (空)
原因说明
大多数场景不需要指定源地址或接口
options 一旦使用:
强依赖网络结构
可移植性差
易引入隐性问题
👉 只在高级判责/多出口环境才用
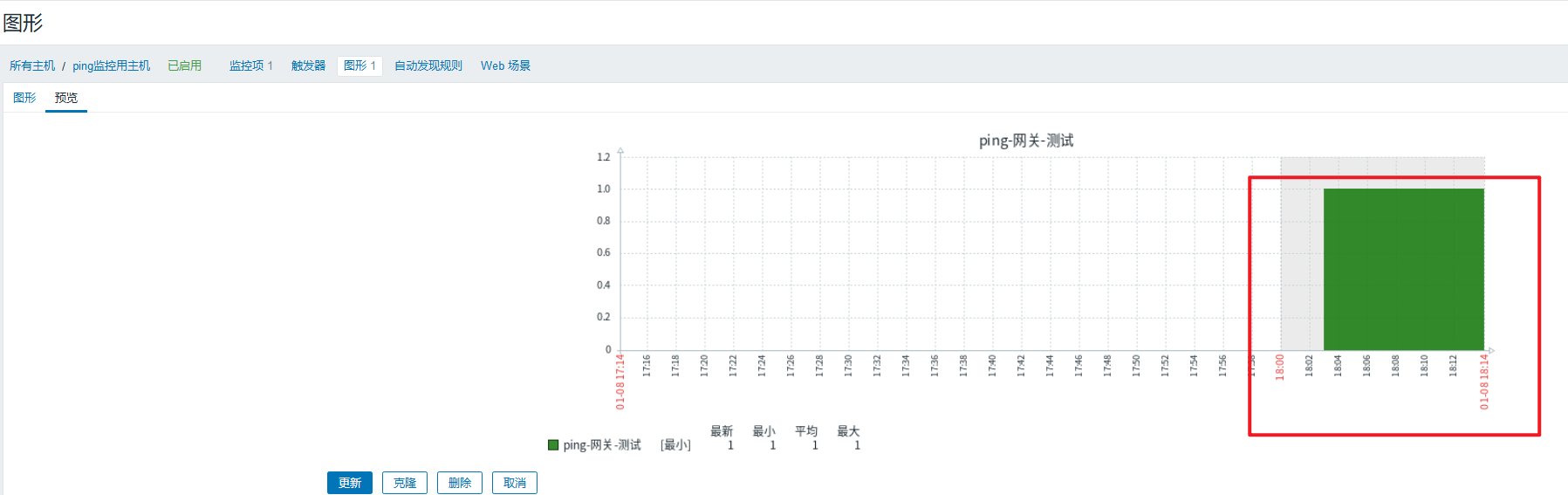
配置好后查看最新数据如下所示
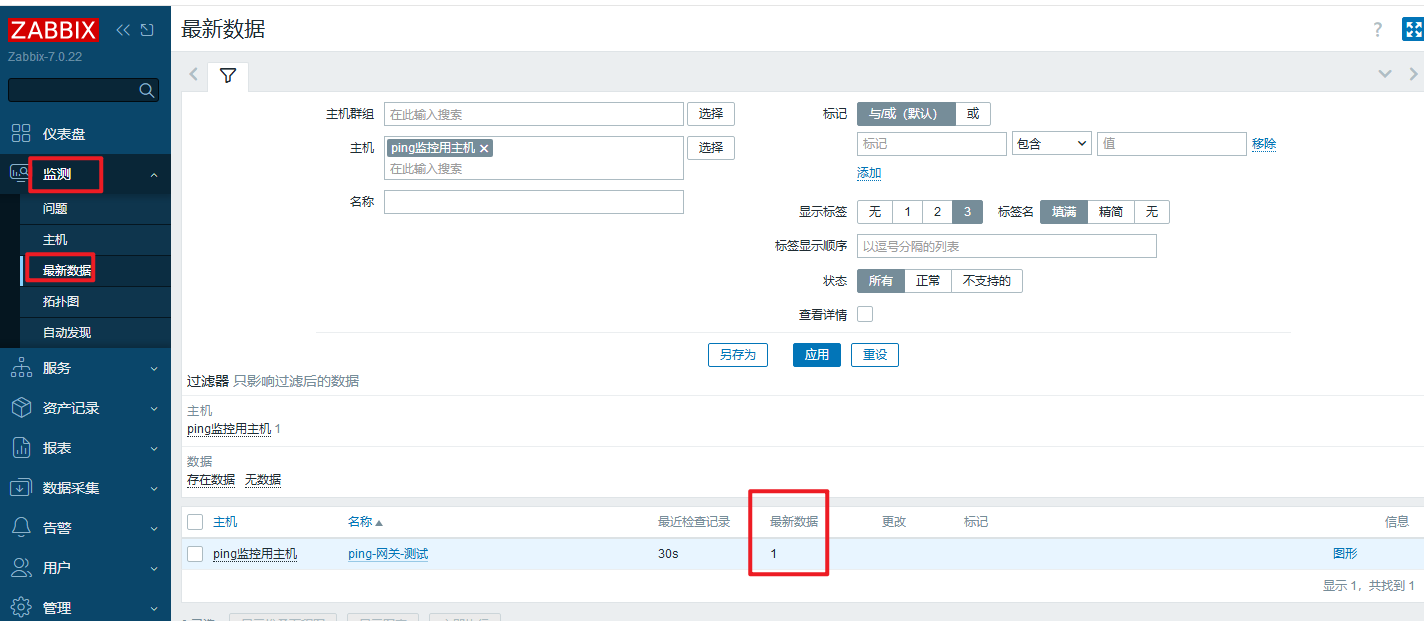
监控项的意思就是:ping 192.168.105.254这个ip,返回结果1为正常,0为部正常
(3)创建监控图形

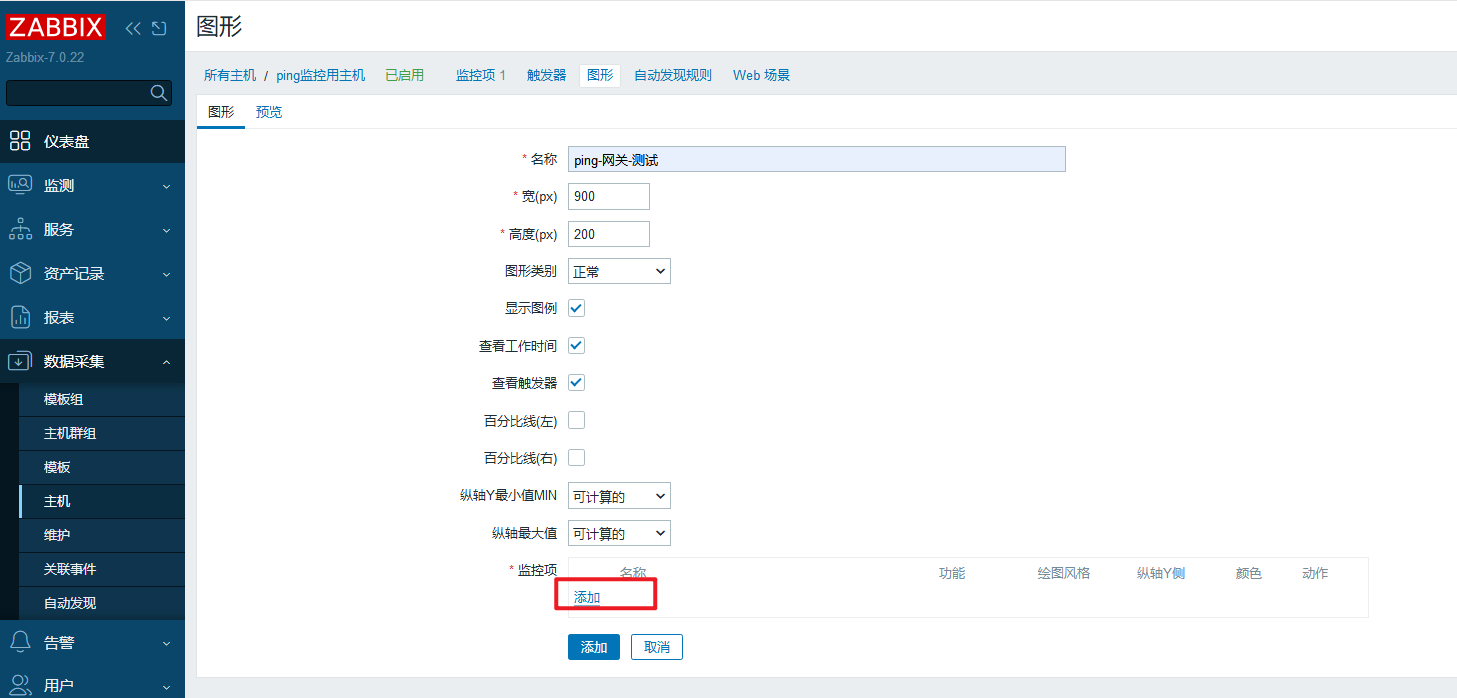
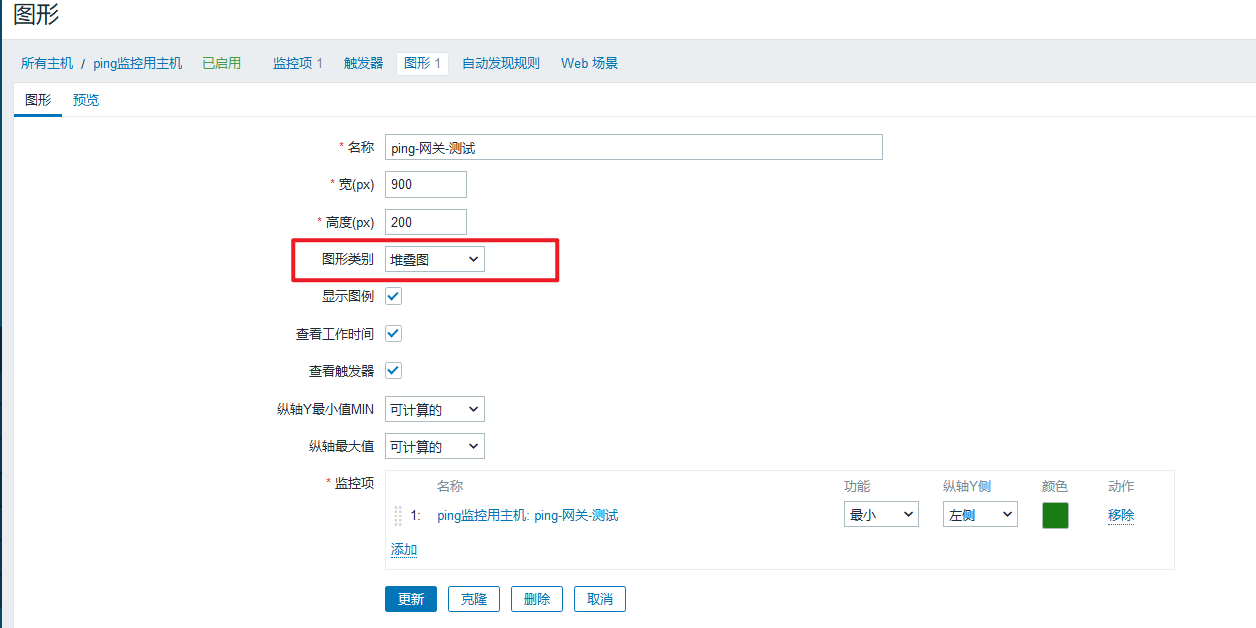
堆叠图要比正常图的显示更清晰直观
10.3、配置触发器
配置触发器-报警
点击刚才的主机,点击【触发器】,在弹出的界面右上方【创建触发器】:
设置警报得级别:严重,灾难
表达式的前半部分代表监控项,后半部分代表运算,
last是只最近的取值,2m代表2分钟,<>代表不等于,1就是值
意思就是:
若取1分钟的最近值,不等于1,则报警
若取2分钟的最近值,等于1,则报警恢复
创建问题表达式和恢复表达式
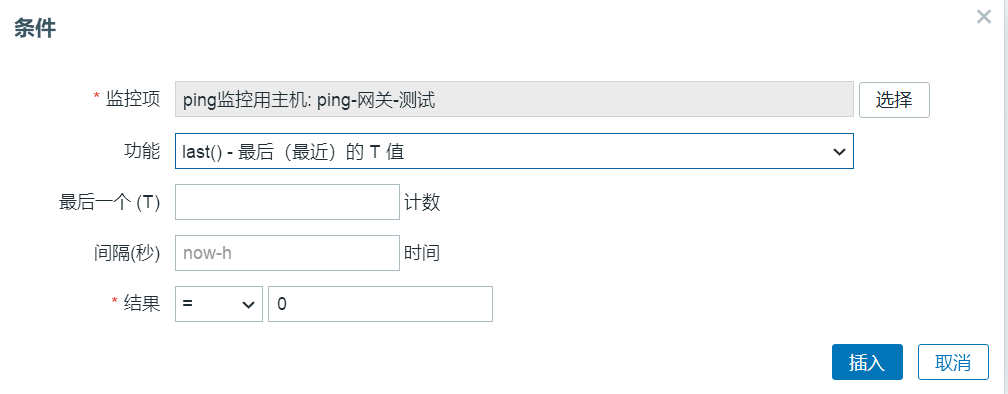
点击恢复表达式可以创建恢复表达式
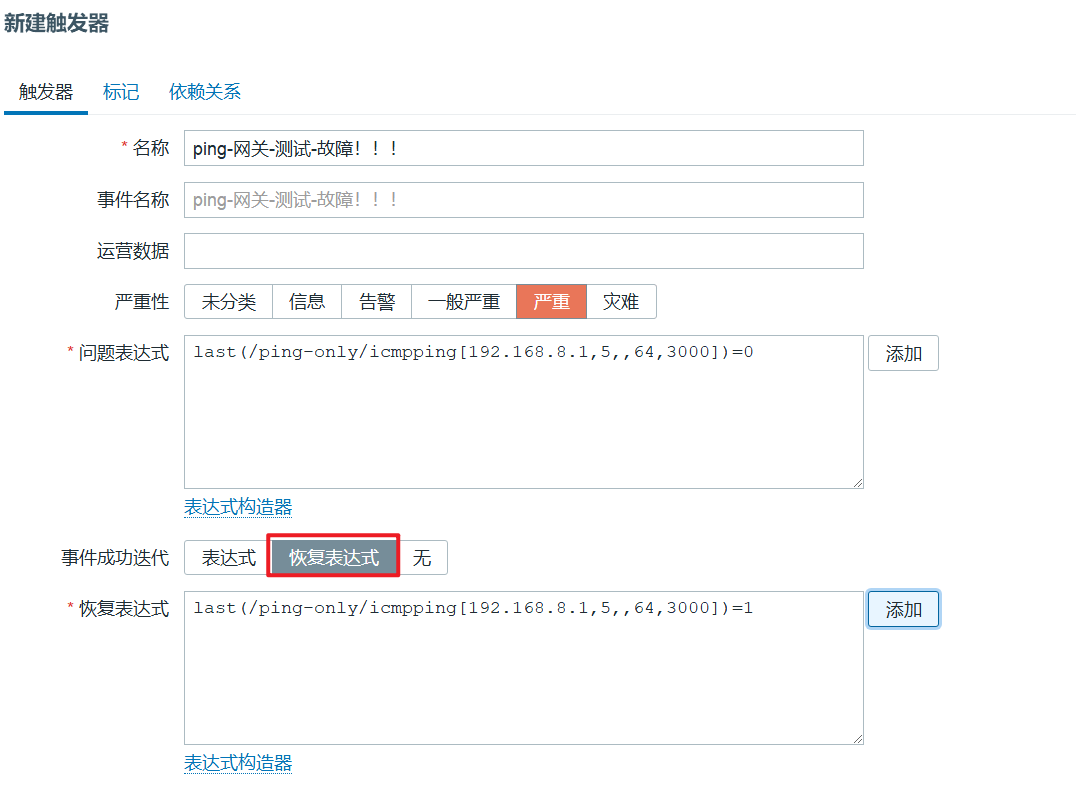
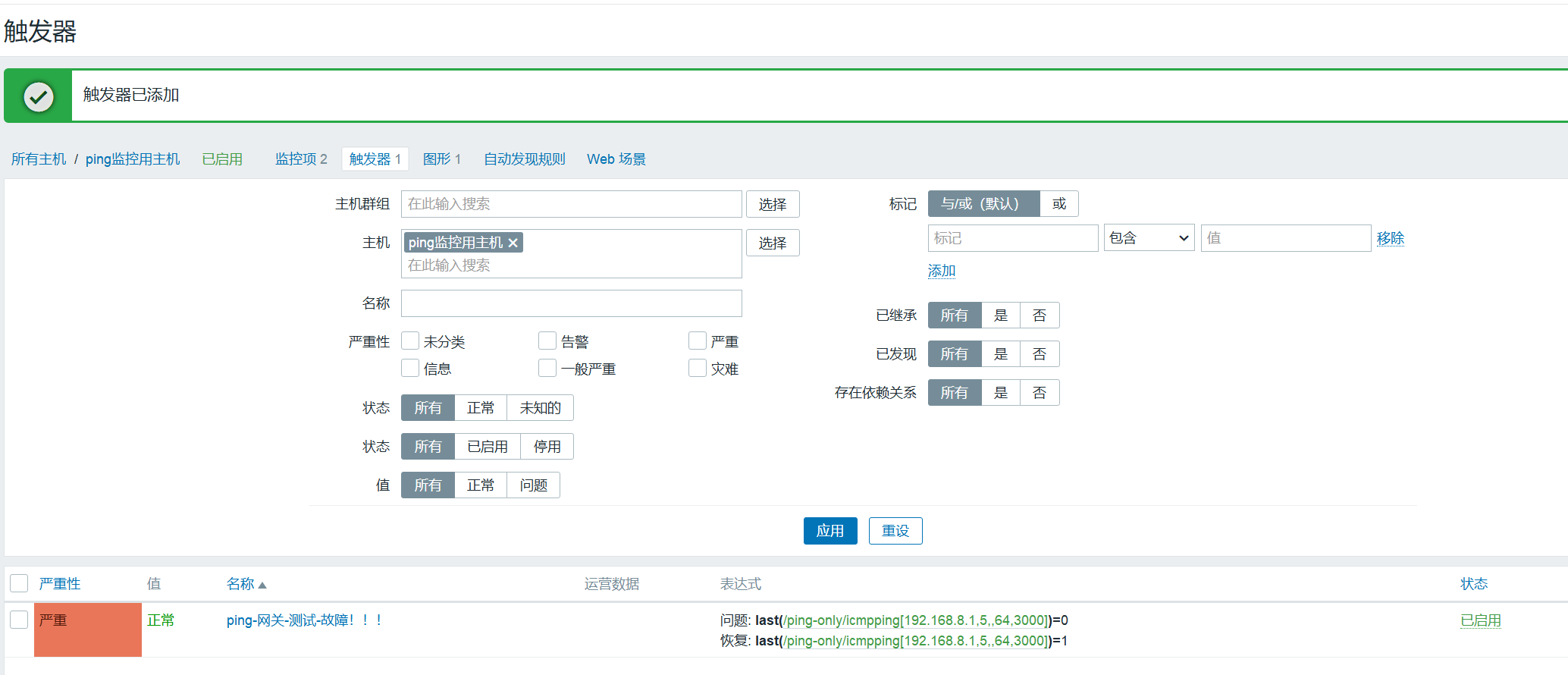
查看配置触发器结果
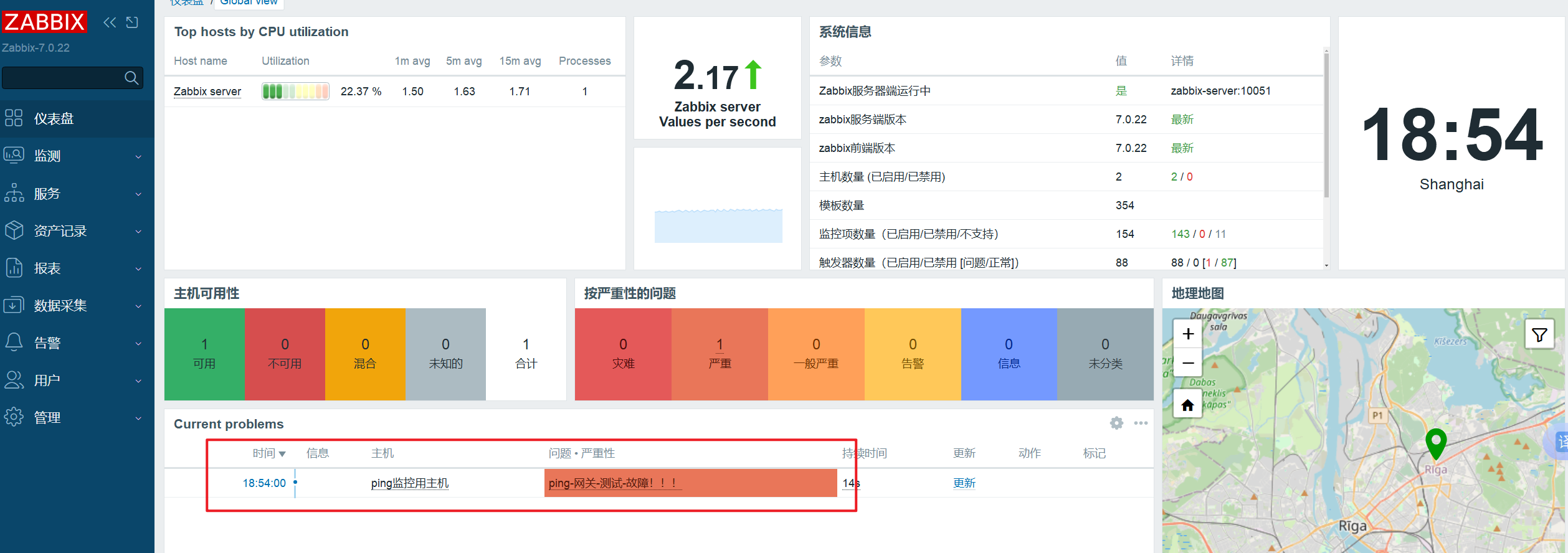
添加报警后,故意关闭指定ping的网络,查看是否报警
点击上方【监测】-【问题】,在网络断开后是否存在报警和报警后是否自动恢复
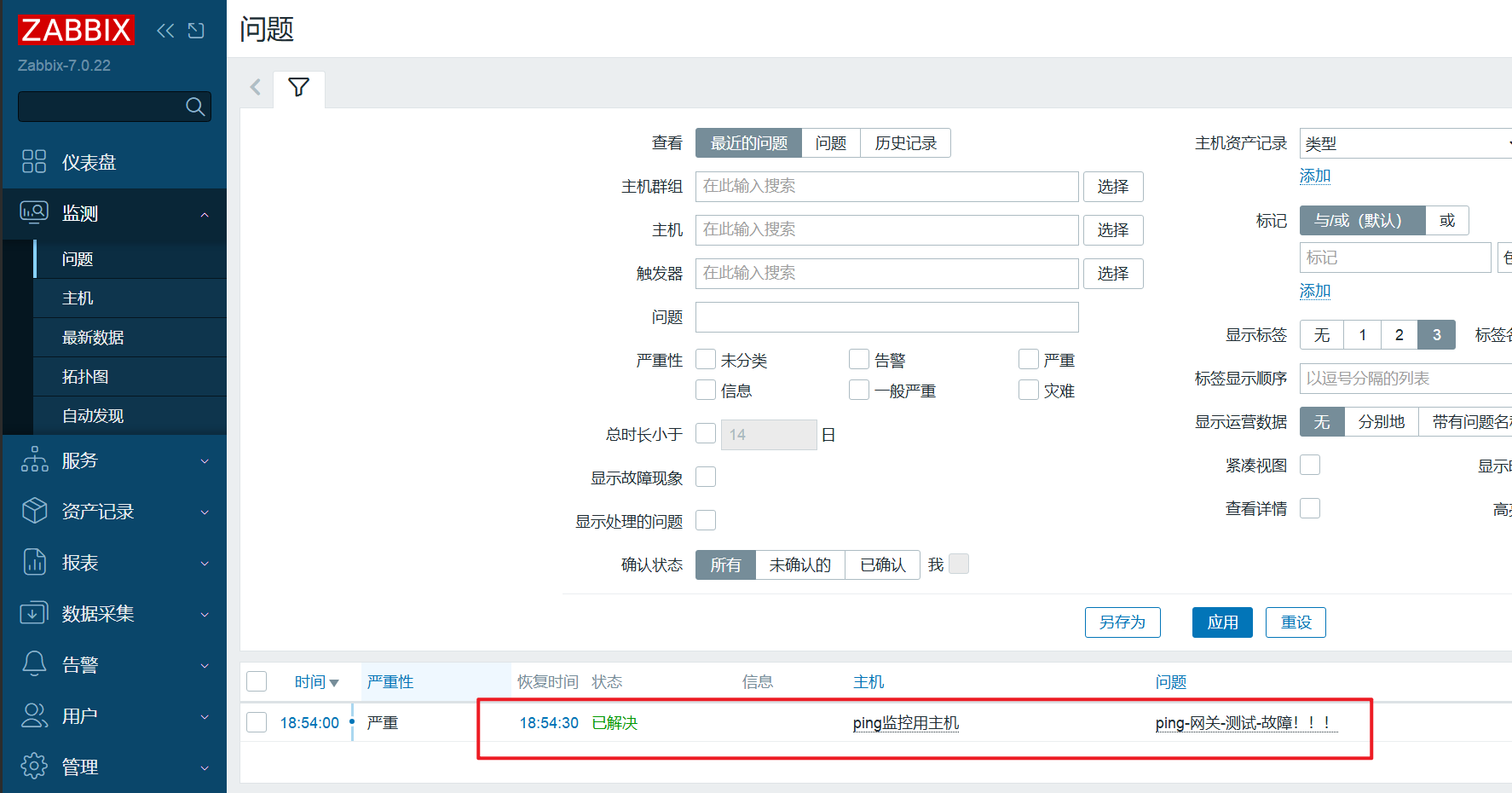
结尾
监控的本质,不是“采集更多指标”,而是在最有限的条件下,把风险变成可见、可控、可追踪。
Ping 看似简单,却是很多企业监控体系里最关键的一层兜底:当 SNMP/Agent 都失效时,它仍然能给你“在线、质量、趋势、告警”的完整闭环。