
如果说以太网是“世界通用语”,
那 InfiniBand,就是“物理学家和 AI 工程师的母语”。
在存储、网络、AI、高性能计算(HPC)领域,有一个协议:
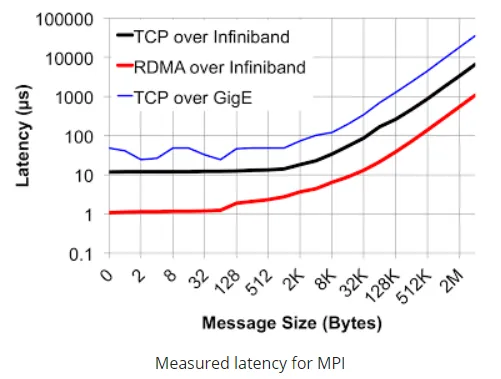
延迟比以太网低一个量级
带宽扩展极其激进
CPU 几乎“感知不到 I/O”
它就是 InfiniBand(IB)。
但奇怪的是——
它从未成为大众网络。
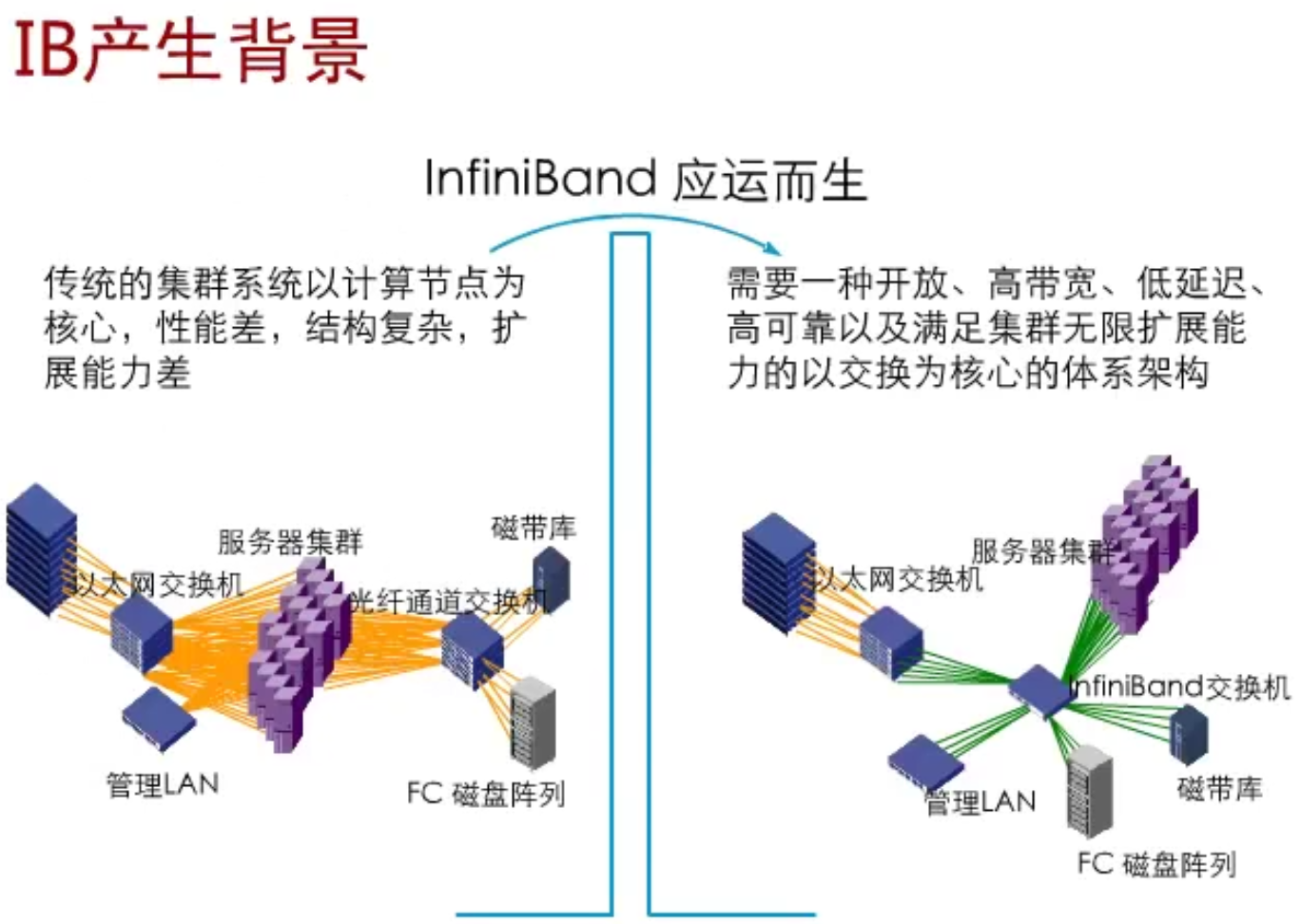
一、什么是 InfiniBand?一句话先立住认知
InfiniBand(简称 IB) 是一种:
专为极低延迟、极高带宽、高并发计算场景设计的高速互连协议
它不是:
局域网(LAN)
互联网协议
传统意义上的“以太网替代品”
一句话定位:
InfiniBand 是为“机器之间像 CPU 内部一样通信”而设计的网络。
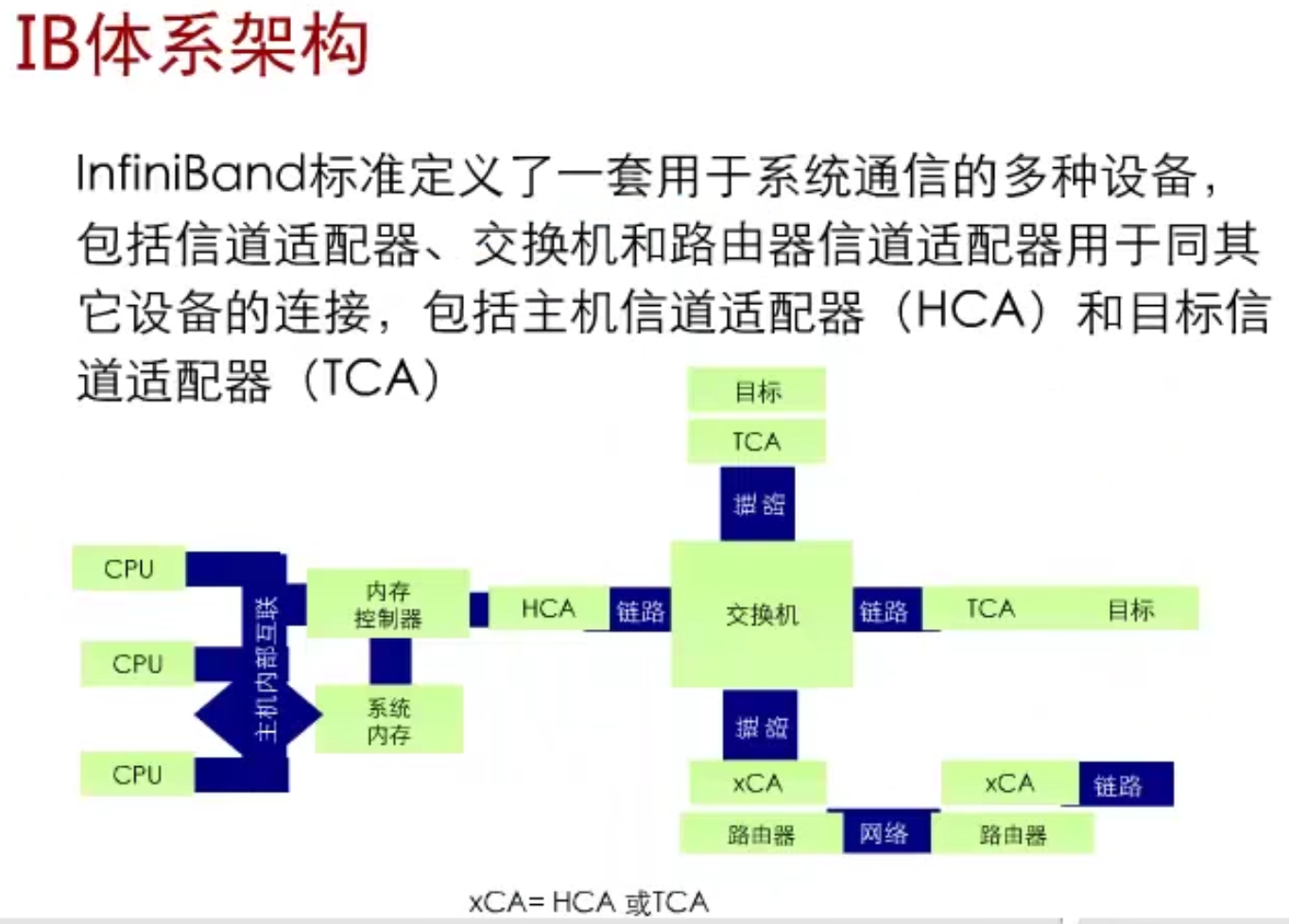
二、IB 是“和什么协议”比较出来的?
InfiniBand 的对照对象,从来不是普通以太网用户,而是:
它解决的不是“通不通”,而是“快不快、稳不稳、算不算得动”。
三、InfiniBand 的前世:为 HPC 而生
1️⃣ 为什么会有 IB?
在 1990s–2000s:
CPU 性能快速提升
集群规模变大
网络成为计算瓶颈
问题很直接:
CPU 算得再快,也在等网络。
传统 TCP/IP 网络:
协议栈太长
中断太多
拷贝次数太多
于是 IB 的设计目标只有一个:
把“网络”从 CPU 的世界里“踢出去”。
2️⃣ IB 的核心设计哲学
IB 的理念非常激进:
不以 IP 为中心
不以操作系统为中心
不以“通用性”为第一目标
它追求的是:
极限性能 + 可预测延迟

四、IB 为什么这么快?核心机制一次讲透
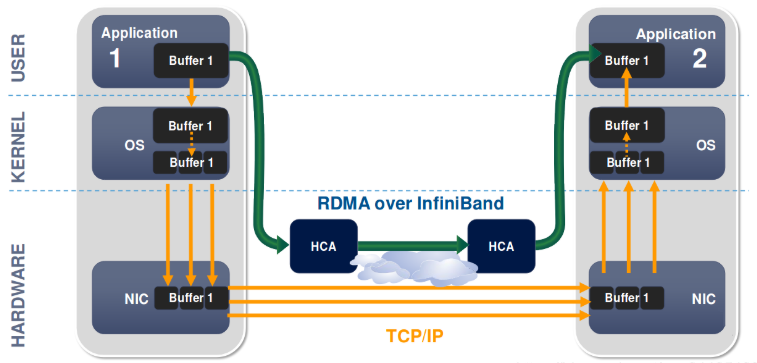
1️⃣ RDMA:IB 的灵魂
InfiniBand 的核心能力是 RDMA(Remote Direct Memory Access)。
它意味着:
远端主机
直接读写本地内存
无需 CPU 参与
无需内核协议栈
类比一句话:
就像你的内存条,突然“长”到了另一台服务器上。
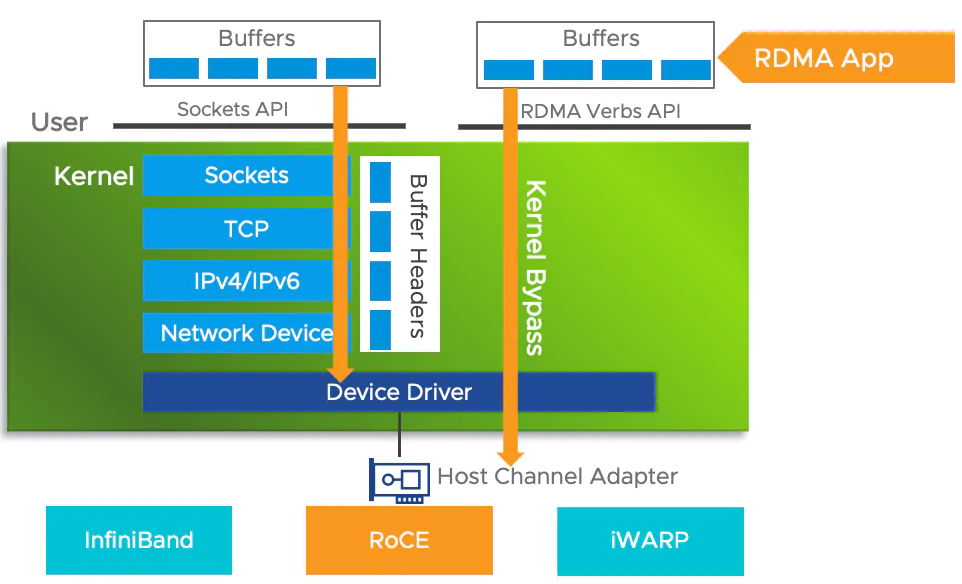
2️⃣ Kernel Bypass(绕过内核)
传统网络路径:
应用 → 内核 → 协议栈 → 网卡IB 的路径:
应用 → HCA(IB 网卡)→ 对端内存没有 socket
没有中断风暴
没有多次拷贝
延迟不是“优化出来的”,而是“路径被删掉了”。
3️⃣ Queue Pair(QP)模型
IB 通信不是“发包”,而是:
建立通信队列
双端共享状态
硬件级调度
通信像“提交任务”,不是“发消息”。
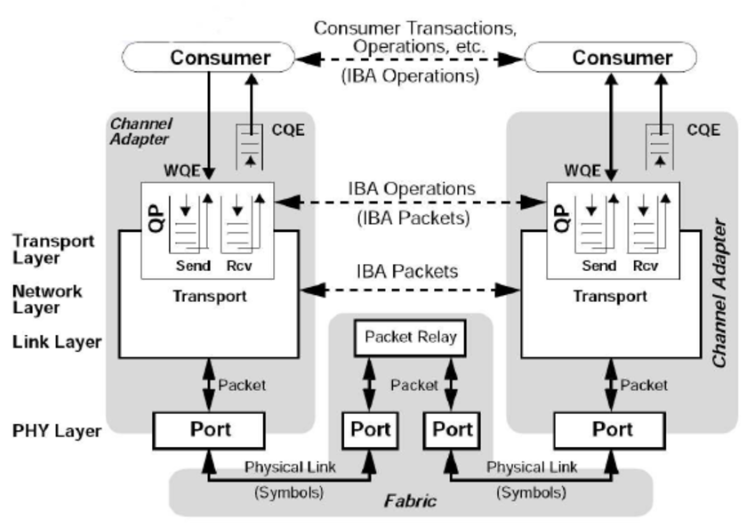
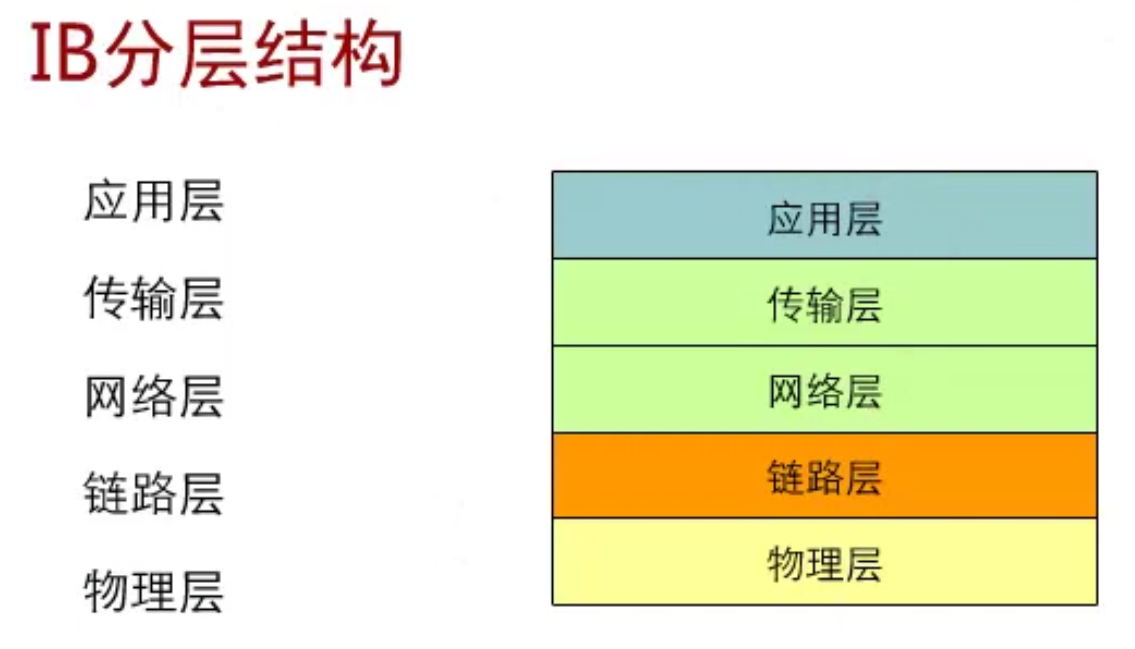
五、InfiniBand 的协议结构(理解版)
InfiniBand 本质是一个完整的系统互连规范:
物理层
链路层
传输层
管理子系统
它甚至定义了:
地址
路由
拥塞控制
错误恢复
IB 更像“分布式计算总线”,而不是网络协议。
六、InfiniBand vs 以太网:不是谁更先进,而是谁更“偏执”
📌 IB 是“为极少数场景做到极致”,以太网是“为所有人做到足够好”。
七、InfiniBand 的典型应用场景
✅ 1️⃣ 高性能计算(HPC)
气象模拟
核物理
生物计算
计算节点之间的“同步成本”极低。
✅ 2️⃣ AI / 大模型训练
GPU 之间 All-Reduce
参数同步
梯度聚合
算力越大,对网络越“残忍”。
✅ 3️⃣ 高端分布式存储
并行文件系统(如 Lustre)
内存级访问
网络不再是“外设”,而是“内存延伸”。
八、为什么 IB 没有“统治世界”?
这是一个非常现实的问题。
❌ 1️⃣ 成本高
专用网卡(HCA)
专用交换机
专用布线
❌ 2️⃣ 学习曲线陡峭
配置复杂
运维要求高
网络工程师门槛高
❌ 3️⃣ 通用性差
不适合普通业务
不适合互联网应用
不适合“随便接一根网线”
IB 从来不是为“普及”而生的。
九、IB 的“今生”:正在被以太网“学习”
今天你看到的很多技术:
RDMA
Kernel Bypass
用户态网络
本质上,都是以太网在“模仿 IB”。
RoCE 的出现,就是最直接的证明:
“我不想要 IB 的成本,但我想要 IB 的能力。”
十、未来:IB 会被取代吗?
一个冷静的判断是:
在极限性能领域,IB 仍然不可替代
在规模化领域,以太网会继续进化
最可能的未来是:
IB 继续守住“性能王座”,
以太网不断蚕食“准高端场景”。
十一、一句话总结
InfiniBand 不是失败者,
它只是从一开始,就没打算服务所有人。
它代表的是:
性能优先
计算优先
工程极限优先
如果你在做:
AI 大模型
HPC
极致性能系统
那么你绕不开 IB。