

写在前面(给小白的一句话)
网络安全应急响应不是“出事了赶紧修”,而是一套事前就设计好的、按步骤执行的专业流程。
真正的高手,不靠临场反应,靠的是模型 + 纪律。
在前两篇中,我们已经讲清楚了:
什么是网络安全事件
为什么必须做应急响应
这一篇,我们进入真正的“实战核心”:
应急响应到底是按什么流程一步一步干的?
一、先给结论:应急响应不是乱来,而是有“标准模型”
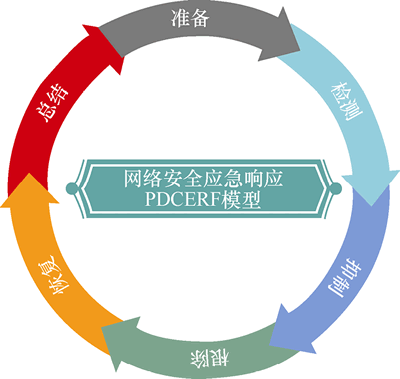
在国际和国内大量安全实践中,有一个被反复验证、非常适合教学和实战的模型:
PDCERF 模型
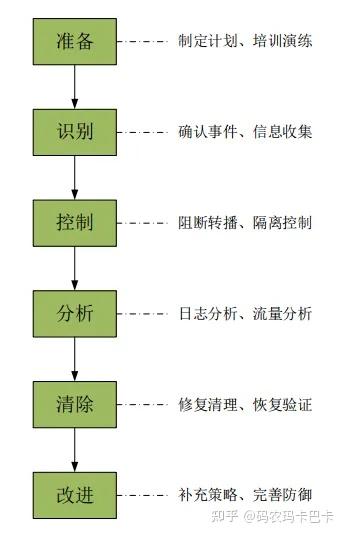
它把网络安全应急响应,拆解成 6 个阶段:
P Preparation 准备
D Detection 发现
C Containment 遏制
E Eradication 根除
R Recovery 恢复
F Follow-up 复盘记住一句话:
没按这 6 步走的应急响应,99% 会留下后遗症。
下面我们一段一段拆,并且每一步都给你一个“现实中的例子”。
二、第 1 阶段:P – Preparation(准备阶段)
真正的应急,从“没出事时”就开始了
1️⃣ 小白最容易忽略的一句话
没有准备的应急响应,本质上是“裸奔”。
准备阶段不是技术细节,而是体系建设。
2️⃣ 准备阶段都准备什么?
✅ 人
谁是应急负责人?
谁能拍板?
谁负责对外沟通?
✅ 制度
应急预案
事件分级标准
汇报路径(几分钟内向谁汇报)
✅ 技术
日志是否留得住?
监控、告警是否可用?
备份是否能恢复?
3️⃣ 现实举例(准备做得好 vs 没准备)
场景:凌晨 2 点发现服务器异常流量
❌ 没准备:
谁处理?不知道
要不要断网?不敢
日志在哪?没开
✅ 有准备:
值班表明确
事件等级直接判定
日志、镜像工具齐全
90% 的“灾难级事故”,死在准备阶段。
三、第 2 阶段:D – Detection(发现阶段)
你得先知道“出事了”,而不是被媒体告诉
1️⃣ 发现不等于“看到病毒”
发现可能来自:
2️⃣ 核心不是“发现”,而是“确认是不是安全事件”
很多小白会犯一个错误:
“一有异常就当成黑客入侵”
专业做法是:
是否偏离正常基线?
是否存在攻击特征?
是否影响业务或数据?
3️⃣ 现实举例
场景:数据库服务器 CPU 持续 100%
❌ 误判:
直接说“被挖矿了”
✅ 正确做法:
查看进程
对比历史基线
结合网络连接、日志
结果可能是:
批处理任务跑飞
但也可能是挖矿木马
Detection 是“技术判断”,不是情绪判断。
四、第 3 阶段:C – Containment(遏制阶段)
核心目标只有一个:别让事情变更糟
1️⃣ 遏制 ≠ 立刻“全网断电”
遏制的本质是:
在尽量不扩大影响的前提下,限制攻击继续发展
2️⃣ 常见遏制手段
3️⃣ 现实举例
场景:发现一台服务器正在向外疯狂发包
❌ 错误做法:
立刻重装系统
✅ 正确顺序:
从网络侧隔离
保留现场(内存 / 日志)
再进入下一阶段
先控住,再处理;先止血,再手术。
五、第 4 阶段:E – Eradication(根除阶段)
找到“病根”,否则一定复发
1️⃣ 根除阶段在干什么?
删除恶意程序
修复漏洞
清理后门
修改被盗凭据
2️⃣ 小白最常犯的致命错误
“删掉病毒就算完事了”
但真正的问题是:
漏洞还在吗?
攻击入口封了吗?
是否还有横向移动?
3️⃣ 现实举例
场景:服务器被植入 WebShell
❌ 错误做法:
删除 WebShell 文件
✅ 正确做法:
找到上传入口
修补程序漏洞
检查其他服务器是否被横向渗透
Eradication 是“系统性清除”,不是文件删除。
六、第 5 阶段:R – Recovery(恢复阶段)
安全恢复,比“恢复运行”更重要
1️⃣ 恢复的目标不是“快”,而是“稳”
恢复阶段关注的是:
业务是否安全恢复
数据是否完整、可信
系统是否处于“干净状态”
2️⃣ 恢复常见方式
3️⃣ 现实举例
场景:核心业务服务器被入侵
❌ 冒进做法:
原地启动服务
✅ 专业做法:
新环境重建
数据校验
分阶段上线
能慢 10 分钟,别快 1 秒。
七、第 6 阶段:F – Follow-up(复盘与改进)
这是“拉开普通运维和专家的分水岭”
1️⃣ 为什么复盘如此重要?
每一次安全事件,都是一次免费的渗透测试。
不复盘 = 白被打。
2️⃣ 复盘要回答的 5 个问题
攻击是怎么进来的?
为什么没早点发现?
哪一步处理得不好?
制度 / 技术哪里不足?
下一次怎么避免?
3️⃣ 现实举例
一次真实复盘结果可能是:
日志保留时间太短
告警阈值设置不合理
人员值班链路不清晰
然后反向推动:
安全加固
流程优化
技术补齐
八、最后总结
记住这 3 句话就够了:
1️⃣ 应急响应不是靠英雄,而是靠流程
2️⃣ 先控局势,再追真相
3️⃣ 不复盘的应急响应,等于没做