
很多人第一次接触存储体系时,都会被一堆词绕晕:块存储、文件存储、分布式存储、对象存储、分布式对象存储、分布式文件系统、分布式块设备……
其实它们不是“互相替代”的关系,而是不同抽象层、不同访问语义、不同工程目标的组合。
下面我用一篇文章把这些概念捋成一条清晰的逻辑链。
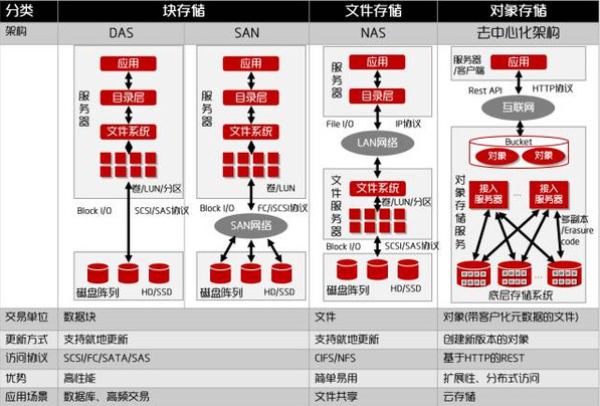
一、什么是块存储?块存储是和什么比较出来的?
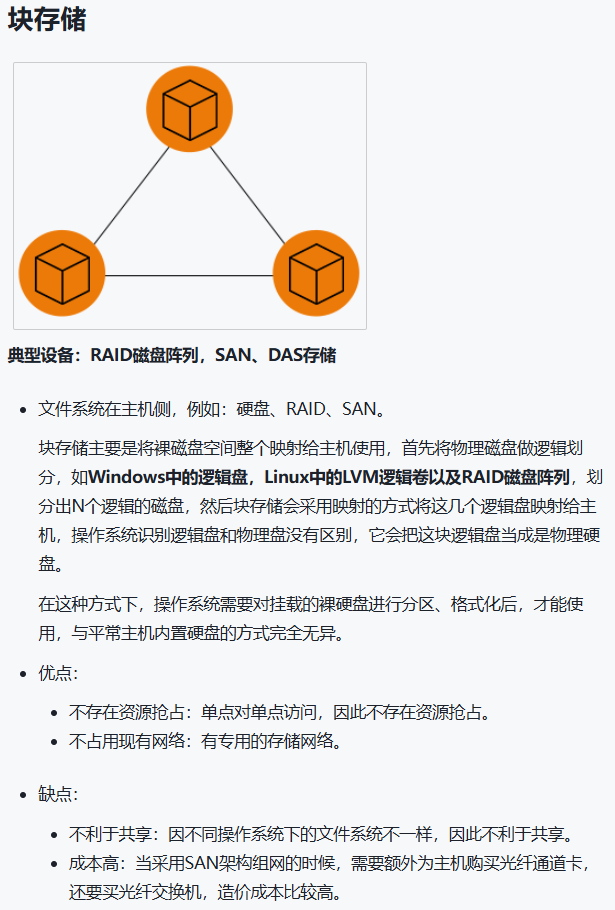
块存储(Block Storage)是一种存储呈现方式:
它把数据切成固定大小的块(block),每个块有地址,像“硬盘扇区/块地址”一样被读写。上层看到的是一块裸磁盘/卷(Volume),而不是“文件”。AWS 的对比解释里也强调:块存储会把数据拆成等大小块并按优化方式存储,适合快速访问与检索。
与之比较的典型是:
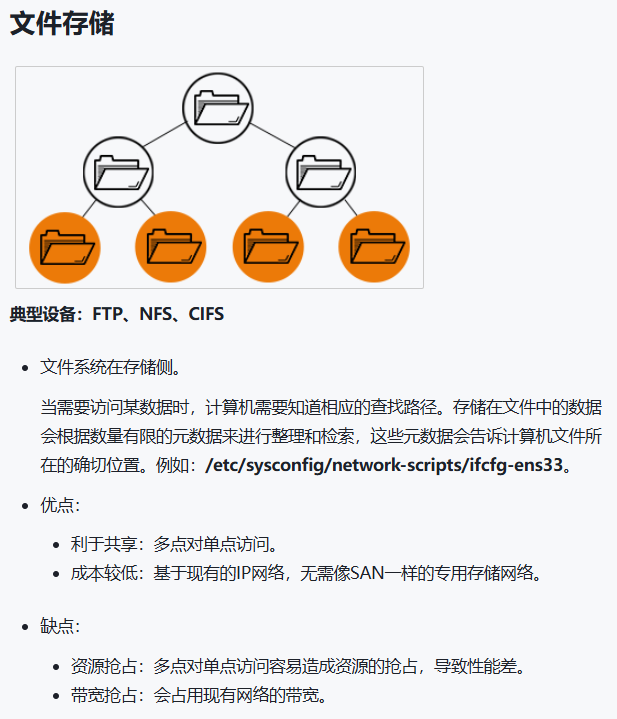
文件存储(File Storage / NAS):上层直接看到“目录/文件”层级。
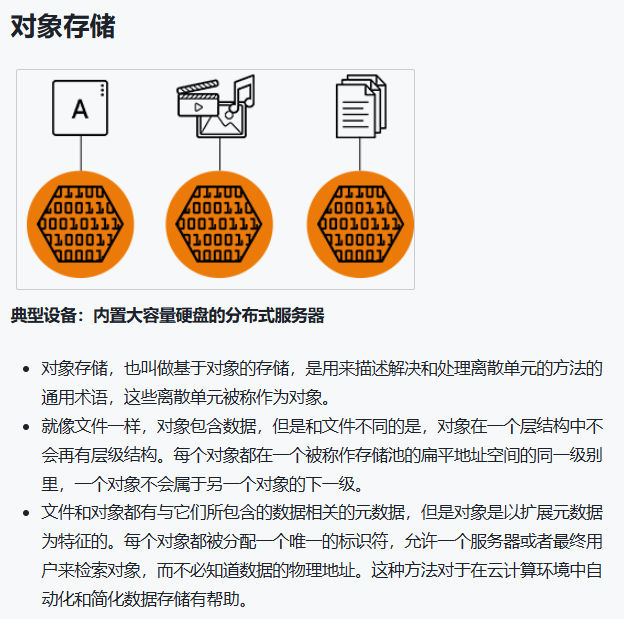
对象存储(Object Storage):上层看到的是“对象 + 元数据 + ID/Key”,不是文件系统目录树。
一句话类比:
块存储:给你一块“生盘”(/dev/sdb),你自己建分区、建文件系统。
文件存储:给你一个“共享文件夹”(/share),你直接读写文件。
对象存储:给你一个“桶 + Key”(bucket/key),你 PUT/GET 对象。
二、块存储“是怎么存的”?
你在主机上看到的“块存储”,通常长这样:
Linux:
/dev/vdb、/dev/mapper/xxxWindows:一块新磁盘(Disk)/ 一个卷(Volume)
1)块存储对主机暴露的是“块设备”
主机拿到的是一个可寻址的块设备,操作系统会在其上:
建分区(可选)
创建文件系统(ext4/xfs/ntfs 等)
由本机文件系统负责目录、权限、文件锁、碎片整理等
也就是说:
✅ 块存储只负责提供“可随机读写的块地址空间”
❗文件语义(文件名、目录、权限)是主机自己实现的。
2)块是“固定大小”,但上层可以随机读写
块存储特别擅长:
随机读写(Random I/O)
低延迟事务写入
细粒度更新(改一个 4KB 页,不用重写整文件)
这也是数据库、虚拟化磁盘镜像偏爱块存储的根本原因。
三、哪些数据“必须”用块存储?(场景清单)
不是所有数据都该用块存储。块存储最适合这类工作负载:
✅ 1)数据库 / 事务型系统(强烈推荐块存储)
MySQL/PostgreSQL/Oracle
ES/ClickHouse(取决于架构,但多数核心数据盘仍偏块)
原因:随机读写、写放大控制、延迟敏感。
✅ 2)虚拟化与云主机系统盘/数据盘
VM 的虚拟磁盘(VMDK/QCOW2 的底层卷)
云主机 EBS/云硬盘这种本质就是块卷
原因:虚拟机需要“像真实硬盘一样”的语义与性能。
✅ 3)高性能文件系统的底座
你想要一个本机 ext4/xfs 的体验(比如应用只认本地路径、锁语义复杂),就让它跑在块存储上。
⚠️ 不太建议块存储的典型数据
海量小图片/视频/归档:对象存储更省心
多人共享文档协作:文件存储(CIFS/NFS)更自然
需要跨机共享同一目录:单纯块卷做不到(除非上层做集群文件系统/共享机制)
四、什么是分布式存储?“分布式”到底指什么?
分布式存储(Distributed Storage)不是一种“访问协议”,而是一种架构方式:
数据不放在一台存储设备里,而是分散到多台节点上,通过复制/纠删码/一致性协议实现容量与可靠性扩展。
关键点:
分布式存储描述的是后端如何组织数据
块/文件/对象描述的是前端如何访问数据
所以它们是两条正交维度:
前端接口:块 / 文件 / 对象
后端架构:单机 / 集群 / 分布式
所谓分布式存储,就是这个底层的存储系统,因为要存放的数据非常多,单一服务器所能连接的物理介质是有限的,提供的IO性能也是有限的,所以通过多台服务器协同工作,每台服务器连接若干物理介质,一起为多个系统提供存储服务。为了满足不同的访问需求,往往一个分布式存储系统,可以同时提供文件存储、块存储和对象存储这三种形式的服务。
五、分布式存储到底是“分布式文件”还是“分布式块”?
答案是:都可以。分布式存储可以对外提供块、文件、对象三种接口。
一个非常典型的例子是 Ceph:
它在同一个分布式底座(RADOS)上,上层可以提供 RBD 块设备、CephFS 文件系统、RGW 对象网关。官方文档与介绍也明确强调这三种接口共存。
1)分布式文件存储(Distributed File Storage)
对外像 NAS:目录/文件
典型:CephFS、GlusterFS、HDFS(偏大数据)
适合:共享目录、协作、容器共享卷(某些场景)
2)分布式块存储(Distributed Block Storage)
对外像“云硬盘”:卷/块设备
典型:Ceph RBD、OpenStack Cinder 后端等
适合:云主机卷、数据库卷、虚拟化
3)分布式对象存储(Distributed Object Storage)
对外像 S3:bucket/object
典型:Ceph RGW、MinIO、各云厂商对象存储
适合:海量非结构化数据、备份归档、静态资源、数据湖
六、对象存储是什么?它和文件存储有什么本质不同?
对象存储的核心特征是:
数据以 对象(Object) 形式管理
每个对象带丰富元数据
用全局唯一 Key/ID 定位,不依赖“目录树”
接口通常是 HTTP/REST(如 S3 API)
AWS 与 Red Hat 都把对象存储描述为:以对象为单位管理数据,并关联元数据,而不是目录文件层级。
对象存储的通用定义也强调:它以对象/Blob 组织数据,区别于文件层级与块寻址。
为什么对象存储特别适合“海量非结构化”?
因为它更容易做到:
横向扩展(bucket/namespace 天生适合跨节点)
便宜的大容量
通过元数据做生命周期管理(分层、归档、版本、保留策略等)
但它通常不擅长:
需要 POSIX 文件锁语义的协作编辑
小延迟事务随机写(对象 PUT/GET 往往以“对象整体”为单位)
七、有“分布式对象存储”一说吗?
不仅有,而且这是对象存储最常见的形态。
原因很简单:对象存储的设计目标往往就是海量扩展与高可靠,天然适合分布式实现。
比如 Ceph 的对象能力就是通过 RGW 提供对象接口,并由分布式集群承载。Ceph 技术架构介绍也把 RGW(对象)、RBD(块)、CephFS(文件)并列为 Ceph 的三大接口层。 (Ceph)
所以你可以这样记:
“对象存储 ≈ 更经常以分布式形态出现”
“文件/块存储”既可以是集中式,也可以是分布式。
八、最容易搞混的点:块/文件/对象 vs 分布式/集中式
把它们放到一个“二维表”里就清楚了:
横轴:访问接口(你怎么用):块 / 文件 / 对象
纵轴:后端架构(它怎么存):集中式 / 分布式
于是会得到 6 种组合:
集中式块:SAN/云硬盘的某些实现
分布式块:Ceph RBD
集中式文件:传统 NAS(CIFS/NFS)
分布式文件:CephFS / GlusterFS
集中式对象:小规模对象存储设备(少见)
分布式对象:S3/Ceph RGW/MinIO(最常见)
九、选型速查:你该用块、文件还是对象?
选块存储(Block)如果你有:
数据库、事务系统
VM 磁盘、系统盘
低延迟随机 I/O
想要完全掌控本机文件系统
选文件存储(File)如果你有:
多人共享目录
办公协作、工程文件共享
需要 POSIX/锁语义(NFS)或 Windows ACL(SMB/CIFS)
选对象存储(Object)如果你有:
海量图片/视频/日志归档/备份
需要生命周期管理、版本、跨地域
以“对象整体”读写为主(PUT/GET)